Proporcionar un ejemplo de codificación sobre cómo realizar la agrupación de clientes de proximidad espacial, aplicable p. cuando se buscan múltiples centros de gravedad (es decir, cuando se desea resolver un problema de ubicación de varios almacenes). La lógica y el enfoque son los mismos que en cualquier tipo de problema de agrupamiento basado en la distancia.
Aplicaré la agrupación en clústeres de k-medias para agrupar clientes en función de su distancia espacial.
El algoritmo para la agrupación de k-medias está bien explicado, p. Ej. por este artículo: https://www.datanovia.com/en/lessons/k-means-clustering-in-r-algorith-and-practical-examples/
Primero defino un marco de datos que contiene coordenadas de latitud y longitud aleatorias, que representan clientes distribuidos al azar.
customer_df <- as.data.frame(matrix(nrow=1000,ncol=2))
colnames(customer_df) <- c("lat","long")
customer_df$lat <- runif(n=1000,min=-90,max=90)
customer_df$long <- runif(n=1000,min=-180,max=180)Aquí ves el encabezado del marco de datos:
head(customer_df)## lat long
## 1 67.260409 47.08063
## 2 55.400065 55.46616
## 3 -47.152065 -107.63843
## 4 -84.266658 -163.62681
## 5 -6.012361 103.34046
## 6 -10.717590 -59.64681El algoritmo de agrupación de k-medias estándar selecciona k puntos iniciales aleatorios y los define como los centros de agrupación. Luego, el algoritmo asigna puntos de datos a cada centro de grupo, basándose en una distancia mínima.
En este caso, queremos utilizar posteriormente el algoritmo de agrupación en clústeres para resolver problemas de ubicación de instalaciones, considerando varios almacenes para ubicar. Por tanto, parece más apropiado seleccionar centros de conglomerados que estén razonablemente distanciados entre sí. Para esto defino una función que elige el número definido de centros de inicio en función de la dimensión de longitud del conjunto de datos espaciales:
initial_centers <- function(customers,centers){
quantiles <- c()
for(i in 1:centers){
quantiles <- c(quantiles,i*as.integer(nrow(customers)/centers))
}
quantiles
}Ahora podemos aplicar la función anterior, en combinación con la función kmeans del paquete base R. En este ejemplo, obtengo cuatro grupos de clientes basados en la proximidad.
cluster_obj <- kmeans(customer_df,centers=customer_df[initial_centers(customer_df,4),])
head(cluster_obj)## $cluster
## [1] 4 4 1 1 2 1 2 4 1 2 1 4 3 4 4 1 1 1 2 2 3 2 1 3 2 3 1 4 2 4 4 2 4 2
## [35] 1 4 4 2 2 1 3 2 2 1 3 2 4 3 2 1 1 2 2 3 4 1 4 2 2 3 2 1 2 1 2 2 2 3
## [69] 1 4 3 3 2 1 4 3 1 1 3 1 2 1 2 1 1 4 2 4 1 2 2 1 4 3 4 2 1 2 3 4 1 2
## [103] 3 3 4 4 4 1 4 3 1 4 1 2 2 1 3 2 3 2 4 3 4 3 2 1 1 2 2 2 4 4 4 1 2 2
## [137] 3 3 2 4 4 3 4 1 1 1 3 3 4 4 1 1 2 4 3 4 4 2 2 1 3 2 4 3 2 1 1 2 1 1
## [171] 2 1 1 1 4 3 3 1 2 3 2 4 2 2 2 4 3 2 1 4 1 2 4 2 3 2 2 2 2 2 1 2 2 1
## [205] 2 1 2 3 3 2 3 1 2 1 2 4 1 1 2 4 3 2 4 2 1 4 4 3 1 1 2 1 2 2 3 2 1 1
## [239] 3 1 3 1 2 1 2 1 1 4 1 1 2 2 1 2 1 4 1 4 2 2 2 2 4 4 1 3 3 1 1 4 3 4
## [273] 4 4 1 2 2 1 4 1 2 4 2 1 4 2 4 2 3 4 4 4 2 2 1 4 2 4 4 1 2 1 2 1 2 3
## [307] 1 1 1 1 2 3 3 3 1 4 4 1 2 1 4 1 4 3 2 4 3 2 1 2 2 4 2 4 2 2 2 4 2 1
## [341] 3 2 1 3 3 2 1 1 3 1 4 1 2 1 4 1 2 3 2 1 4 2 3 1 3 1 1 2 2 2 2 2 1 3
## [375] 2 2 1 2 4 4 1 3 1 2 3 4 2 4 4 1 1 2 4 4 4 2 3 4 1 3 2 3 4 1 3 3 1 4
## [409] 2 1 4 1 3 2 1 3 3 2 2 2 1 2 3 1 2 4 4 2 2 4 3 4 3 1 1 3 1 3 4 2 4 3
## [443] 3 3 4 1 1 2 1 3 2 1 1 2 1 4 2 2 1 1 2 1 2 4 2 4 3 2 1 1 1 4 2 3 1 4
## [477] 3 1 2 1 1 1 2 3 4 3 2 3 4 4 2 1 3 2 1 4 4 2 4 2 3 1 2 2 3 4 2 3 2 4
## [511] 3 4 2 4 2 1 3 2 1 4 2 4 3 1 1 4 2 2 2 1 4 2 1 3 1 4 1 4 2 3 4 3 1 2
## [545] 2 2 2 2 2 2 2 2 4 4 1 4 1 2 2 1 1 1 2 3 3 1 1 2 2 3 4 3 2 2 2 1 1 3
## [579] 4 2 1 4 1 3 3 1 1 1 2 3 1 2 3 1 4 4 1 1 3 1 4 1 2 3 3 2 4 4 2 4 2 2
## [613] 2 3 1 1 4 2 3 4 1 4 4 2 2 1 4 3 3 4 4 1 1 3 4 3 1 1 2 3 3 3 3 1 1 1
## [647] 4 1 2 1 2 4 2 4 2 2 3 4 4 2 4 1 2 1 1 4 2 1 1 2 1 4 4 1 3 3 1 3 4 4
## [681] 2 2 4 3 1 2 3 2 4 3 2 4 3 4 1 4 4 1 3 1 3 3 4 2 1 4 4 2 2 2 2 3 1 1
## [715] 1 2 1 4 1 3 1 2 2 4 3 3 2 2 1 3 2 2 1 1 3 4 3 3 1 1 2 1 1 4 2 4 1 4
## [749] 2 2 2 2 3 1 2 1 1 1 2 1 3 2 1 3 2 3 2 2 1 2 4 3 4 1 4 2 3 1 3 1 3 2
## [783] 3 1 1 1 1 1 4 2 2 1 2 1 4 1 4 3 4 1 2 1 1 4 2 1 4 4 3 4 2 3 1 3 2 3
## [817] 1 3 4 2 4 1 3 2 1 3 3 1 1 1 1 4 2 2 4 1 1 3 4 1 2 3 2 4 1 1 1 3 2 2
## [851] 1 3 3 2 3 1 2 2 3 2 1 4 1 1 1 3 2 1 3 1 2 3 2 4 2 2 2 2 1 3 4 3 1 4
## [885] 2 3 2 2 3 4 4 2 2 1 3 4 4 1 4 4 3 1 2 4 2 1 1 1 2 4 3 1 1 3 1 3 1 1
## [919] 4 3 1 2 1 3 2 4 2 1 4 2 1 3 1 2 1 3 3 1 2 1 1 1 1 1 1 3 4 4 2 1 2 2
## [953] 2 1 1 1 4 2 3 4 3 4 1 2 3 3 1 4 2 1 1 3 1 3 4 1 3 1 3 1 3 3 1 4 3 4
## [987] 1 3 2 4 4 2 3 4 3 2 4 2 3 2
##
## $centers
## lat long
## 1 0.6938018 -122.442238
## 2 -5.3567099 123.957813
## 3 -46.9979863 -2.714282
## 4 48.9979562 15.062099
##
## $totss
## [1] 13050174
##
## $withinss
## [1] 1108924.4 1028012.3 423675.5 523506.7
##
## $tot.withinss
## [1] 3084119
##
## $betweenss
## [1] 9966055Arriba verá el encabezado del objeto de resultado devuelto por la función kmeans. A continuación, combino los índices de clúster contenidos por el objeto kmeans con el marco de datos del cliente, de modo que ahora tenemos 3 columnas. Esto nos permitirá hacer ggplots, etc.
result_df <- customer_df
result_df$group <- cluster_obj$cluster
head(result_df)## lat long group
## 1 67.260409 47.08063 4
## 2 55.400065 55.46616 4
## 3 -47.152065 -107.63843 1
## 4 -84.266658 -163.62681 1
## 5 -6.012361 103.34046 2
## 6 -10.717590 -59.64681 1Completo esta publicación visualizando los resultados en un ggplot (diagrama de dispersión usando el paquete ggplot2 R). Para colorear utilicé el paquete viridis en R:
library(ggplot2)
library(viridis)ggplot(result_df) + geom_point(mapping = aes(x=lat,y=long,color=group)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 
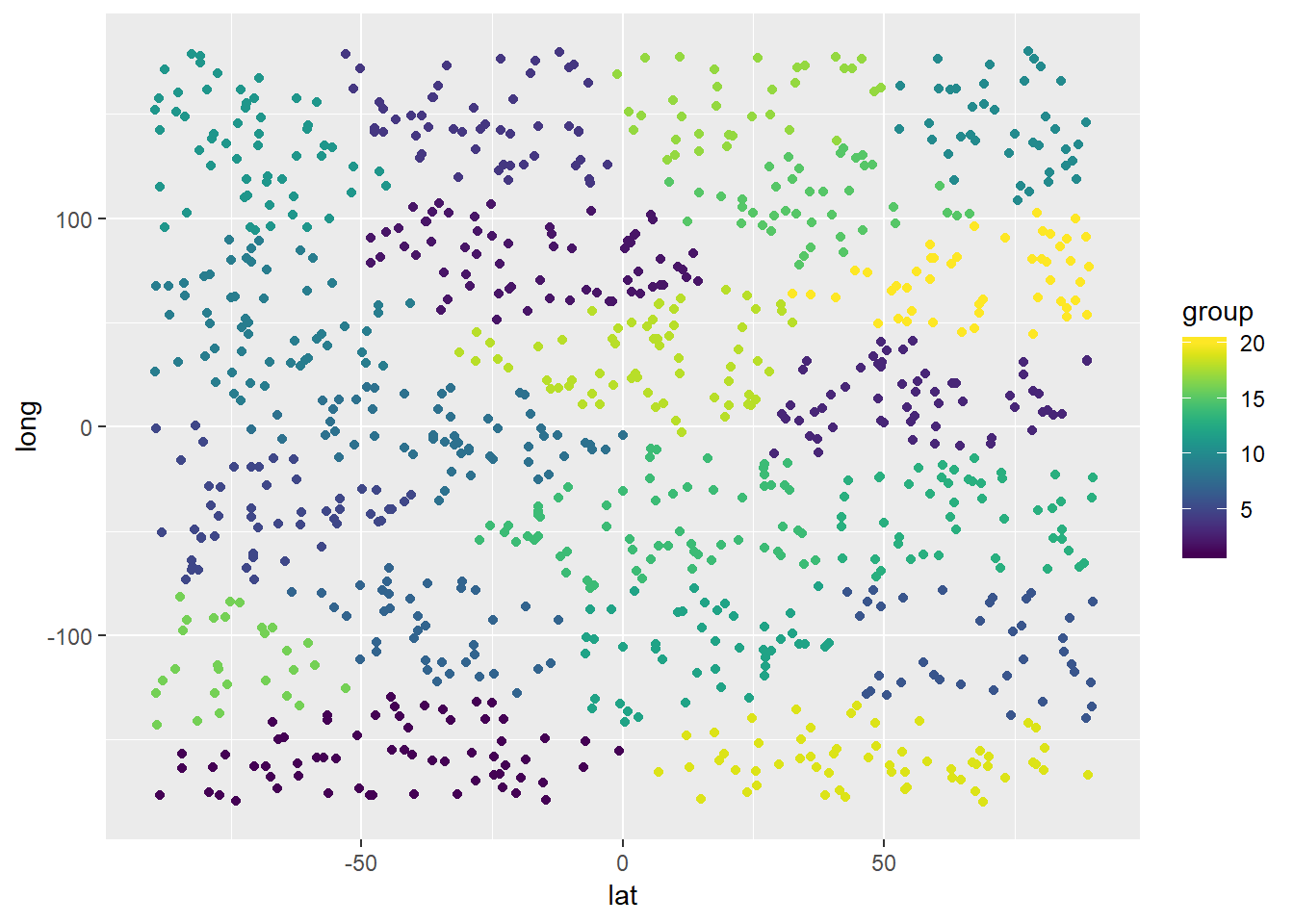
Hagamos otra prueba con 20 almacenes:
cluster_obj <- kmeans(customer_df,centers=customer_df[initial_centers(customer_df,20),])
result_df$group <- cluster_obj$cluster
ggplot(result_df) + geom_point(mapping = aes(x=lat,y=long,color=group)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 
Si está interesado, consulte mi publicación sobre el cálculo del centro de masa en R y cómo se puede usar para resolver un problema de ubicación de almacén en R.

Ingeniero industrial especializado en optimización y simulación (R, Python, SQL, VBA)



Leave a Reply