I tidligere indlæg har jeg demonstreret, hvordan du kan få adgang til aktiekursdata med f.eks. pandas_datareader i Python. I dette indlæg vil jeg præsentere en algoritme, som du kan konstruere en effektiv portefølje af aktier med. Algoritmen bestemmer den optimale andel af hver aktie i din portefølje baseret på det ønskede risikoniveau.
Mere præcist vil jeg præsentere en metode til visualisering af den effektive grænse for teoretisk mulige aktieporteføljer bestående af et specifikt sæt aktier. I dette eksempel vil jeg arbejde med følgende aktier fra fragtbranchen:
- Yamato Holdings (YATRY)
- Knight-Swift Transportation Holdings (KNX)
- BEST (BEST)
- YRC Worldwide (YRCW)
- Schneider National (SNDR)
- Old Dominion Freight Line (ODFL)
- Arc Best (ARCB)
- Werner Enterprises (WERN)
Risiko måles i dette indlæg som standardafvigelse af historisk afkast. Afkast måles som det gennemsnitlige historiske daglige aktieafkast (ved hjælp af sammenligning af daglige aktieslutkurser).
Jeg starter med at importere relevante moduler i Python:
# importer relevante moduler import pandas as pd import numpy as np import pandas_datareader.data as web import datetime import matplotlib.pyplot as plt import statistics as stat import random as rnd from matplotlib.ticker import StrMethodFormatter
Jeg ønsker at indsamle historiske aktiekursdata for de foregående 6 måneder. Nedenfor angiver jeg start- og slutdato for den relevante periode, hvortil data så indsamles:
# specificer relevant start- og slutdato for aktieprisdataindsamlingsperioden start_date = datetime.datetime(2020,4,1) end_date = datetime.datetime(2020,9,30)
Dernæst definerer jeg en hjælpefunktion, som indsamler en dataramme for aktiekurser fra Yahoo Finance via pandas_datareader. Funktionen oversætter de indsamlede aktiekursdata til daglige afkast:
# definer funktion, der returnerer en liste med daglige returneringer
def returns(df):
prices = df["Close"]
returns = [0 if i == 0 else (prices[i]-prices[i-1])/(prices[i-1]) for i in range(0,len(prices))]
return(returns)
Nu definerer jeg en anden hjælpefunktion, som indsamler og opsætter en liste over aktienavne og beregner deres gennemsnitlige daglige afkast og deres standardafvigelse af daglige afkast over en bestemt periode. Også denne funktion gør brug af pandas_datareader til at indsamle aktiekursdata fra Yahoo Finance:
# definer funktion, der kan konstruere dataramme med standardafvigelser og gennemsnitlige daglige afkast
def analyzeStocks(tickersArr,start_date,end_date):
# Opret tom datarammeskabelon
index = ["ticker","return","stdev"]
muArr = []
sigmaArr = []
# løb gennem alle tickers
for i in range(0,len(tickersArr)):
# tilføj ticker til tabellen
tick = tickersArr[i]
# få aktiekursdata
data = web.DataReader(tickersArr[i],"yahoo",start_date,end_date)
# beregne gennemsnitligt dagligt afkast
muArr.append(stat.mean(returns(data)))
# beregne standardafvigelse
sigmaArr.append(stat.stdev(returns(data)))
# returner en dataramme
return(pd.DataFrame(np.array([tickersArr, muArr, sigmaArr]),index=index,columns=tickersArr))
De følgende aktier, med de følgende aktiemærker, undersøges i dette indlæg:
tickersArr = ["YATRY","KNX","BEST","YRCW","SNDR","ODFL","ARCB","WERN"]
Ved hjælp af ovenstående aktiemærker (tickers) udfører jeg analyseStocks for at trække aktiekursdata og beregne de gennemsnitlige daglige afkast og dertilhørende standardafvigelse:
base_df = analyzeStocks(tickersArr,start_date,end_date) base_df
| YATRY | KNX | BEST | YRCW | SNDR | ODFL | ARCB | WERN | |
|---|---|---|---|---|---|---|---|---|
| ticker | YATRY | KNX | BEST | YRCW | SNDR | ODFL | ARCB | WERN |
| return | 0.004653743523196298 | 0.0023175179239564793 | -0.0034124339485902665 | 0.011159199755783849 | 0.002462051717055063 | 0.003349259316178459 | 0.005861686829084918 | 0.0017903742321965712 |
| stdev | 0.02358463699374274 | 0.02114091659162514 | 0.031397841155750277 | 0.09455276239906354 | 0.019372571935633416 | 0.023305461738410294 | 0.037234069177970675 | 0.02237976138155402 |
Ved hjælp af matplotlib laver jeg et simpelt spredningsdiagram over de enkelte aktiers historiske afkast og standardafvigelse:
plt.figure(figsize=(15,8))
muArr = [float(i) for i in base_df.iloc[1,]]
sigmaArr = [float(i) for i in base_df.iloc[2,]]
sharpeArr = [muArr[i]/sigmaArr[i] for i in range(0,len(muArr))]
plt.scatter(sigmaArr,muArr,c=sharpeArr,cmap="plasma")
plt.title("Historical avg. returns vs. standard deviations [single stocks]",size=22)
plt.xlabel("Standard deviation",size=14)
plt.ylabel("Avg. daily return",size=14)
Text(0, 0.5, 'Avg. daily return')

Nu definerer jeg en funktion til porteføljeopbygning. Funktionen opretter et defineret antal porteføljer med tilfældigt tildelt aktievægtning. Det forventede afkast og standardafvigelsen for daglige afkast som følge heraf returneres i form af en Pandas-dataramme:
# definer funktion til oprettelse af defineret antal porteføljer
def portfolioBuilder(n,tickersArr,start_date,end_date):
muArr = []
sigmaArr = []
dailyreturnsArr = []
weightedreturnsArr = []
portfoliodailyreturnsArr = []
# udfyld daglige afkast
for i in range(0,len(tickersArr)):
data = web.DataReader(tickersArr[i],"yahoo",start_date,end_date)
dailyreturnsArr.append(returns(data))
# Opret n forskellige porteføljer
for i in range(0,n):
# nulstil daglig porteføljeliste
portfoliodailyreturnsArr = []
# Opret porteføljevægt
weightsArr = [rnd.uniform(0,1) for i in range(0,len(tickersArr))]
nweightsArr = [i/sum(weightsArr) for i in weightsArr]
# vægt det daglige afkast
for j in range(0,len(dailyreturnsArr[0])):
temp = 0
for k in range(0,len(tickersArr)):
temp = temp + float(dailyreturnsArr[k][j])*float(nweightsArr[k])
portfoliodailyreturnsArr.append(temp)
# beregne og tilføje mavg daglige vægtede porteføljeafkast
muArr.append(stat.mean(portfoliodailyreturnsArr))
# beregn standardafvigelse for den vægtede porteføljes daglige afkast
sigmaArr.append(stat.stdev(portfoliodailyreturnsArr))
# returnerer forventet afkast og standardafvigelse for de oprettede porteføljer
return([sigmaArr,muArr])
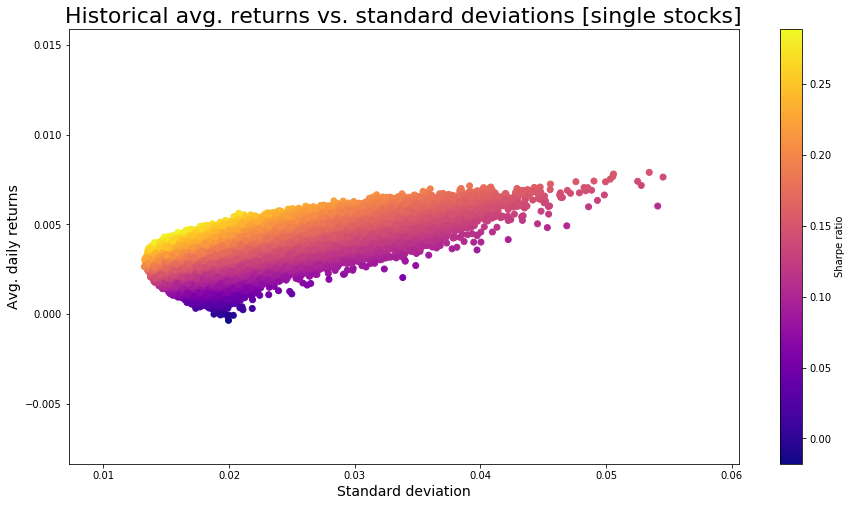
Jeg anvender porteføljebygningsfunktionen til tickerne og plotter resultatet ved hjælp af 500.000 tilfældige porteføljer ved hjælp af matplotlib.pyplot:
portfoliosArr = portfolioBuilder(500000,tickersArr,start_date,end_date)
plt.figure(figsize=(15,8))
muArr = [float(portfoliosArr[1][i]) for i in range(0,len(portfoliosArr[1]))]
sigmaArr = [float(portfoliosArr[0][i]) for i in range(0,len(portfoliosArr[0]))]
sharpeArr = [muArr[i]/sigmaArr[i] for i in range(0,len(muArr))]
plt.scatter(sigmaArr,muArr,c=sharpeArr,cmap="plasma")
plt.title("Historical avg. returns vs. standard deviations [single stocks]",size=22)
plt.colorbar(label="Sharpe ratio")
plt.xlabel("Standard deviation",size=14)
plt.ylabel("Avg. daily returns",size=14)
Text(0, 0.5, 'Avg. daily returns')

Dette diagram giver dig mulighed for at validere om din nuværende aktievægtning er effektivt. Effektivt vægtede porteføljer vil ligger placeret langs den øverste linje i spredningsdiagrammet.

Industriingeniør som gerne beskæftiger sig med optimering, simulation og matematisk modellering i R, SQL, VBA og Python



Leave a Reply