In früheren Beiträgen habe ich gezeigt, wie Aktienkursdaten mit pandas_datareader in Python heruntergeladen werden können – direkt aus Python.
In diesem Beitrag werde ich einen Algorithmus vorstellen mit dem Sie ein effizientes Portfolio basierend auf einer Reihe von Aktien erstellen können, die Sie möglicherweise in Betracht ziehen. Der Algorithmus ermittelt den optimalen Anteil jeder Aktie in Ihrem Portfolio auf der Grundlage des Risikos, das Sie sicher eingehen.
Genauer gesagt werde ich eine Methode zur Visualisierung der effizienten Grenze von Portfolios vorstellen, die aus einem bestimmten Satz von Aktien bestehen. In diesem Beispiel werde ich mit den folgenden 8 Aktien arbeiten, die alle Speditionen sind:
- Yamato Holdings (YATRY)
- Knight-Swift Transportation Holdings (KNX)
- BEST (BEST)
- YRC Worldwide (YRCW)
- Schneider National (SNDR)
- Old Dominion Freight Line (ODFL)
- Arc Best (ARCB)
- Werner Enterprises (WERN)
Das Risiko wird als Standardabweichung der historischen Renditen gemessen. Die Rendite wird als durchschnittliche historische tägliche Aktienrendite (unter Verwendung der Schlusskurse) gemessen.
Ich beginne mit dem Import einiger relevanter Module in Python:
# relevante Module importieren import pandas as pd import numpy as np import pandas_datareader.data as web import datetime import matplotlib.pyplot as plt import statistics as stat import random as rnd from matplotlib.ticker import StrMethodFormatter
Ich möchte historische Aktienkursdaten für die letzten 6 Monate sammeln. Im Folgenden gebe ich das Start- und Enddatum des relevanten Zeitraums an, um Daten zu sammeln von:
# Geben Sie das relevante Start- und Enddatum für den Erfassungszeitraum der Aktienkursdaten an start_date = datetime.datetime(2020,4,1) end_date = datetime.datetime(2020,9,30)
Als Nächstes definiere ich eine Hilfsfunktion die einen von Yahoo Finance über pandas_datareader gesammelten Aktienkursdatenrahmen aufnimmt und in tägliche Renditen transformiert:
# Funktion definieren, die eine Liste der täglichen Rückgaben zurückgibt
def returns(df):
prices = df["Close"]
returns = [0 if i == 0 else (prices[i]-prices[i-1])/(prices[i-1]) for i in range(0,len(prices))]
return(returns)Jetzt definiere ich eine weitere Hilfsfunktion. Diese Funktion nimmt eine Liste von Aktien-Ticks auf und berechnet deren durchschnittliche tägliche Rendite sowie die dazugehörige Standardabweichung. Diese Funktion verwendet pandas_datareader um Aktienkursdaten von Yahoo abzufragen:
# Funktion definieren, die einen Datenrahmen mit Standardabweichungen und durchschnittlichen täglichen Erträgen erstellen kann
def analyzeStocks(tickersArr,start_date,end_date):
# Leere Datenrahmenvorlage erstellen
index = ["ticker","return","stdev"]
muArr = []
sigmaArr = []
# Durchlaufe alle Ticker
for i in range(0,len(tickersArr)):
# Ticker zur Tabelle hinzufügen
tick = tickersArr[i]
# Aktienkursdaten abrufen
data = web.DataReader(tickersArr[i],"yahoo",start_date,end_date)
# Berechne die durchschnittliche tägliche Rendite
muArr.append(stat.mean(returns(data)))
# Standardabweichung berechnen
sigmaArr.append(stat.stdev(returns(data)))
# einen Datenrahmen zurückgeben
return(pd.DataFrame(np.array([tickersArr, muArr, sigmaArr]),index=index,columns=tickersArr))In diesem Beitrag möchte ich die folgenden Ticker-Zeichen analysieren:
tickersArr = ["YATRY","KNX","BEST","YRCW","SNDR","ODFL","ARCB","WERN"]
Mit den obigen Tickern führe ich analyseStocks aus – um Aktienkursdaten abzurufen und die durchschnittliche Rendite und Standardabweichung zu berechnen.
base_df = analyzeStocks(tickersArr,start_date,end_date) base_df
| YATRY | KNX | BEST | YRCW | SNDR | ODFL | ARCB | WERN | |
|---|---|---|---|---|---|---|---|---|
| ticker | YATRY | KNX | BEST | YRCW | SNDR | ODFL | ARCB | WERN |
| return | 0.004653743523196298 | 0.0023175179239564793 | -0.0034124339485902665 | 0.011159199755783849 | 0.002462051717055063 | 0.003349259316178459 | 0.005861686829084918 | 0.0017903742321965712 |
| stdev | 0.02358463699374274 | 0.02114091659162514 | 0.031397841155750277 | 0.09455276239906354 | 0.019372571935633416 | 0.023305461738410294 | 0.037234069177970675 | 0.02237976138155402 |
Mit Matplotlib mache ich ein einfaches Streudiagramm der historischen Rendite gegenüber der historischen Volatilität:
plt.figure(figsize=(15,8))
muArr = [float(i) for i in base_df.iloc[1,]]
sigmaArr = [float(i) for i in base_df.iloc[2,]]
sharpeArr = [muArr[i]/sigmaArr[i] for i in range(0,len(muArr))]
plt.scatter(sigmaArr,muArr,c=sharpeArr,cmap="plasma")
plt.title("Historical avg. returns vs. standard deviations [single stocks]",size=22)
plt.xlabel("Standard deviation",size=14)
plt.ylabel("Avg. daily return",size=14)
Text(0, 0.5, 'Avg. daily return')

Jetzt definiere ich eine Portfolioaufbaufunktion. Die Funktion erstellt eine definierte Anzahl von Portfolios mit zufällig zugewiesenen Aktiengewichtungen. Die daraus resultierende erwartete Rendite und Standardabweichung wird in Form eines Pandas-Datenrahmens zurückgegeben:
# Funktion zum Erstellen einer definierten Anzahl von Portfolios definieren
def portfolioBuilder(n,tickersArr,start_date,end_date):
muArr = []
sigmaArr = []
dailyreturnsArr = []
weightedreturnsArr = []
portfoliodailyreturnsArr = []
# tägliche Renditen ausfüllen
for i in range(0,len(tickersArr)):
data = web.DataReader(tickersArr[i],"yahoo",start_date,end_date)
dailyreturnsArr.append(returns(data))
# n verschiedene Portfolios erstellen
for i in range(0,n):
# tägliche Portfolio-Liste zurücksetzen
portfoliodailyreturnsArr = []
# Portfoliogewicht erstellen
weightsArr = [rnd.uniform(0,1) for i in range(0,len(tickersArr))]
nweightsArr = [i/sum(weightsArr) for i in weightsArr]
# Gewicht die täglichen Renditen
for j in range(0,len(dailyreturnsArr[0])):
temp = 0
for k in range(0,len(tickersArr)):
temp = temp + float(dailyreturnsArr[k][j])*float(nweightsArr[k])
portfoliodailyreturnsArr.append(temp)
# Berechnen und Anhängen der täglichen gewichteten Portfoliorenditen
muArr.append(stat.mean(portfoliodailyreturnsArr))
# Berechnen und Anhängen der Standardabweichung der täglichen Renditen des gewichteten Portfolios
sigmaArr.append(stat.stdev(portfoliodailyreturnsArr))
# erwartete Renditen und Standardabweichung für die erstellten Portfolios zurückgeben
return([sigmaArr,muArr])
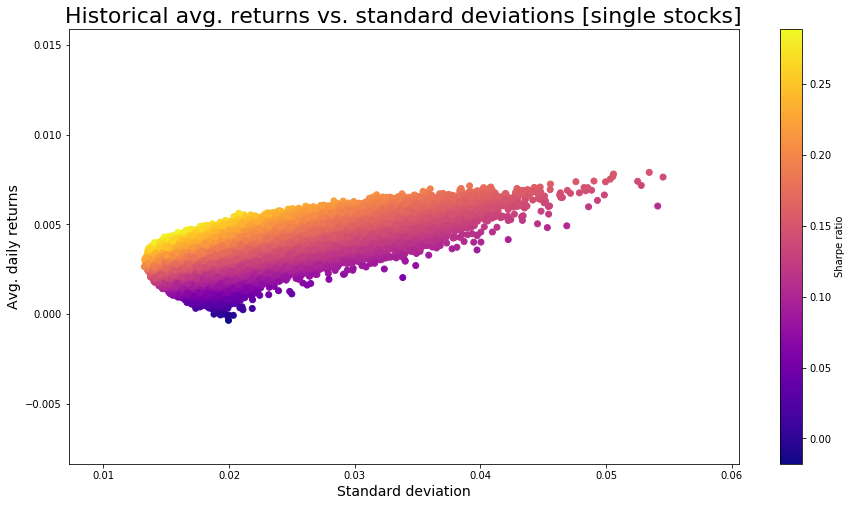
Ich wende die Funktion an um 500000 zufällige Portfolios basierend auf den angegebenen Ticker-Symbolen zu erzeugen. Die Visualisierung erfolgt mittels Matplotlib.pyplot:
portfoliosArr = portfolioBuilder(500000,tickersArr,start_date,end_date)
plt.figure(figsize=(15,8))
muArr = [float(portfoliosArr[1][i]) for i in range(0,len(portfoliosArr[1]))]
sigmaArr = [float(portfoliosArr[0][i]) for i in range(0,len(portfoliosArr[0]))]
sharpeArr = [muArr[i]/sigmaArr[i] for i in range(0,len(muArr))]
plt.scatter(sigmaArr,muArr,c=sharpeArr,cmap="plasma")
plt.title("Historical avg. returns vs. standard deviations [single stocks]",size=22)
plt.colorbar(label="Sharpe ratio")
plt.xlabel("Standard deviation",size=14)
plt.ylabel("Avg. daily returns",size=14)
Text(0, 0.5, 'Avg. daily returns')

Mit dieser Graphik kann ein Analyst überprüfen ob dessen aktuelle Auswahl an Aktiengewichtungen für die ausgewählten Aktien derzeit effizient ist. Effiziente Portfolios befinden sich entlang der oberen Linie in dem Streudiagramm.

Wirtschaftsingenieur mit Interesse an Optimierung, Simulation und mathematischer Modellierung in R, SQL, VBA und Python



Leave a Reply