Bereitstellen eines Codierungsbeispiels für die Durchführung von Kunden-Clustering in räumlicher Nähe, anwendbar z. B. bei der Suche nach mehreren Schwerpunkten (dh wenn ein Problem mit mehreren Lagerstandorten gelöst werden soll). Die Logik und der Ansatz sind die gleichen wie bei jeder Art von entfernungsbasiertem Clustering-Problem.
Ich werde K-Means-Clustering anwenden, um Kunden basierend auf ihrer räumlichen Entfernung zu gruppieren.
Der Algorithmus für k-Means-Clustering ist gut erklärt, z. B. in diesem Artikel: https://www.datanovia.com/en/lessons/k-means-clustering-in-r-algorith-and-practical-examples/
Zuerst definiere ich einen Datenrahmen, der zufällige Breiten- und Längenkoordinaten enthält, die zufällig verteilte Kunden darstellen.
customer_df <- as.data.frame(matrix(nrow=1000,ncol=2))
colnames(customer_df) <- c("lat","long")
customer_df$lat <- runif(n=1000,min=-90,max=90)
customer_df$long <- runif(n=1000,min=-180,max=180)Hier sehen Sie den Header des Datenrahmens:
head(customer_df)## lat long
## 1 67.260409 47.08063
## 2 55.400065 55.46616
## 3 -47.152065 -107.63843
## 4 -84.266658 -163.62681
## 5 -6.012361 103.34046
## 6 -10.717590 -59.64681Der standardmäßige k-Means-Clustering-Algorithmus wählt k zufällige Anfangspunkte aus und definiert diese als Clusterzentren. Der Algorithmus ordnet dann jedem Clusterzentrum basierend auf der minimalen Entfernung Datenpunkte zu.
In diesem Fall möchten wir später den Clustering-Algorithmus zum Lösen von Standortproblemen von Einrichtungen verwenden, wobei mehrere zu lokalisierende Lagerhäuser in Betracht gezogen werden. I erscheint es daher sinnvoller, Clusterzentren auszuwählen, die angemessen voneinander entfernt sind. Dazu definiere ich eine Funktion, die die definierte Anzahl von Startzentren basierend auf der Längendimension des Geodatensatzes auswählt:
initial_centers <- function(customers,centers){
quantiles <- c()
for(i in 1:centers){
quantiles <- c(quantiles,i*as.integer(nrow(customers)/centers))
}
quantiles
}Wir können jetzt die obige Funktion in Kombination mit der kmeans-Funktion aus dem R-Basispaket anwenden. In diesem Beispiel leite ich vier nähebasierte Kundengruppen ab.
cluster_obj <- kmeans(customer_df,centers=customer_df[initial_centers(customer_df,4),])
head(cluster_obj)## $cluster
## [1] 4 4 1 1 2 1 2 4 1 2 1 4 3 4 4 1 1 1 2 2 3 2 1 3 2 3 1 4 2 4 4 2 4 2
## [35] 1 4 4 2 2 1 3 2 2 1 3 2 4 3 2 1 1 2 2 3 4 1 4 2 2 3 2 1 2 1 2 2 2 3
## [69] 1 4 3 3 2 1 4 3 1 1 3 1 2 1 2 1 1 4 2 4 1 2 2 1 4 3 4 2 1 2 3 4 1 2
## [103] 3 3 4 4 4 1 4 3 1 4 1 2 2 1 3 2 3 2 4 3 4 3 2 1 1 2 2 2 4 4 4 1 2 2
## [137] 3 3 2 4 4 3 4 1 1 1 3 3 4 4 1 1 2 4 3 4 4 2 2 1 3 2 4 3 2 1 1 2 1 1
## [171] 2 1 1 1 4 3 3 1 2 3 2 4 2 2 2 4 3 2 1 4 1 2 4 2 3 2 2 2 2 2 1 2 2 1
## [205] 2 1 2 3 3 2 3 1 2 1 2 4 1 1 2 4 3 2 4 2 1 4 4 3 1 1 2 1 2 2 3 2 1 1
## [239] 3 1 3 1 2 1 2 1 1 4 1 1 2 2 1 2 1 4 1 4 2 2 2 2 4 4 1 3 3 1 1 4 3 4
## [273] 4 4 1 2 2 1 4 1 2 4 2 1 4 2 4 2 3 4 4 4 2 2 1 4 2 4 4 1 2 1 2 1 2 3
## [307] 1 1 1 1 2 3 3 3 1 4 4 1 2 1 4 1 4 3 2 4 3 2 1 2 2 4 2 4 2 2 2 4 2 1
## [341] 3 2 1 3 3 2 1 1 3 1 4 1 2 1 4 1 2 3 2 1 4 2 3 1 3 1 1 2 2 2 2 2 1 3
## [375] 2 2 1 2 4 4 1 3 1 2 3 4 2 4 4 1 1 2 4 4 4 2 3 4 1 3 2 3 4 1 3 3 1 4
## [409] 2 1 4 1 3 2 1 3 3 2 2 2 1 2 3 1 2 4 4 2 2 4 3 4 3 1 1 3 1 3 4 2 4 3
## [443] 3 3 4 1 1 2 1 3 2 1 1 2 1 4 2 2 1 1 2 1 2 4 2 4 3 2 1 1 1 4 2 3 1 4
## [477] 3 1 2 1 1 1 2 3 4 3 2 3 4 4 2 1 3 2 1 4 4 2 4 2 3 1 2 2 3 4 2 3 2 4
## [511] 3 4 2 4 2 1 3 2 1 4 2 4 3 1 1 4 2 2 2 1 4 2 1 3 1 4 1 4 2 3 4 3 1 2
## [545] 2 2 2 2 2 2 2 2 4 4 1 4 1 2 2 1 1 1 2 3 3 1 1 2 2 3 4 3 2 2 2 1 1 3
## [579] 4 2 1 4 1 3 3 1 1 1 2 3 1 2 3 1 4 4 1 1 3 1 4 1 2 3 3 2 4 4 2 4 2 2
## [613] 2 3 1 1 4 2 3 4 1 4 4 2 2 1 4 3 3 4 4 1 1 3 4 3 1 1 2 3 3 3 3 1 1 1
## [647] 4 1 2 1 2 4 2 4 2 2 3 4 4 2 4 1 2 1 1 4 2 1 1 2 1 4 4 1 3 3 1 3 4 4
## [681] 2 2 4 3 1 2 3 2 4 3 2 4 3 4 1 4 4 1 3 1 3 3 4 2 1 4 4 2 2 2 2 3 1 1
## [715] 1 2 1 4 1 3 1 2 2 4 3 3 2 2 1 3 2 2 1 1 3 4 3 3 1 1 2 1 1 4 2 4 1 4
## [749] 2 2 2 2 3 1 2 1 1 1 2 1 3 2 1 3 2 3 2 2 1 2 4 3 4 1 4 2 3 1 3 1 3 2
## [783] 3 1 1 1 1 1 4 2 2 1 2 1 4 1 4 3 4 1 2 1 1 4 2 1 4 4 3 4 2 3 1 3 2 3
## [817] 1 3 4 2 4 1 3 2 1 3 3 1 1 1 1 4 2 2 4 1 1 3 4 1 2 3 2 4 1 1 1 3 2 2
## [851] 1 3 3 2 3 1 2 2 3 2 1 4 1 1 1 3 2 1 3 1 2 3 2 4 2 2 2 2 1 3 4 3 1 4
## [885] 2 3 2 2 3 4 4 2 2 1 3 4 4 1 4 4 3 1 2 4 2 1 1 1 2 4 3 1 1 3 1 3 1 1
## [919] 4 3 1 2 1 3 2 4 2 1 4 2 1 3 1 2 1 3 3 1 2 1 1 1 1 1 1 3 4 4 2 1 2 2
## [953] 2 1 1 1 4 2 3 4 3 4 1 2 3 3 1 4 2 1 1 3 1 3 4 1 3 1 3 1 3 3 1 4 3 4
## [987] 1 3 2 4 4 2 3 4 3 2 4 2 3 2
##
## $centers
## lat long
## 1 0.6938018 -122.442238
## 2 -5.3567099 123.957813
## 3 -46.9979863 -2.714282
## 4 48.9979562 15.062099
##
## $totss
## [1] 13050174
##
## $withinss
## [1] 1108924.4 1028012.3 423675.5 523506.7
##
## $tot.withinss
## [1] 3084119
##
## $betweenss
## [1] 9966055Oben sehen Sie den Header des von der kmeans-Funktion zurückgegebenen Ergebnisobjekts. Unten kombiniere ich die im kmeans-Objekt enthaltenen Cluster-Indizes mit dem Kundendatenrahmen, sodass wir jetzt 3 Spalten haben. Dadurch können wir ggplots usw. erstellen.
result_df <- customer_df
result_df$group <- cluster_obj$cluster
head(result_df)## lat long group
## 1 67.260409 47.08063 4
## 2 55.400065 55.46616 4
## 3 -47.152065 -107.63843 1
## 4 -84.266658 -163.62681 1
## 5 -6.012361 103.34046 2
## 6 -10.717590 -59.64681 1Ich vervollständige diesen Beitrag, indem ich die Ergebnisse in einem ggplot (Scatterplot mit dem ggplot2 R-Paket) visualisiere. Zum Färben habe ich das viridis-Paket in R verwendet:
library(ggplot2)
library(viridis)ggplot(result_df) + geom_point(mapping = aes(x=lat,y=long,color=group)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 
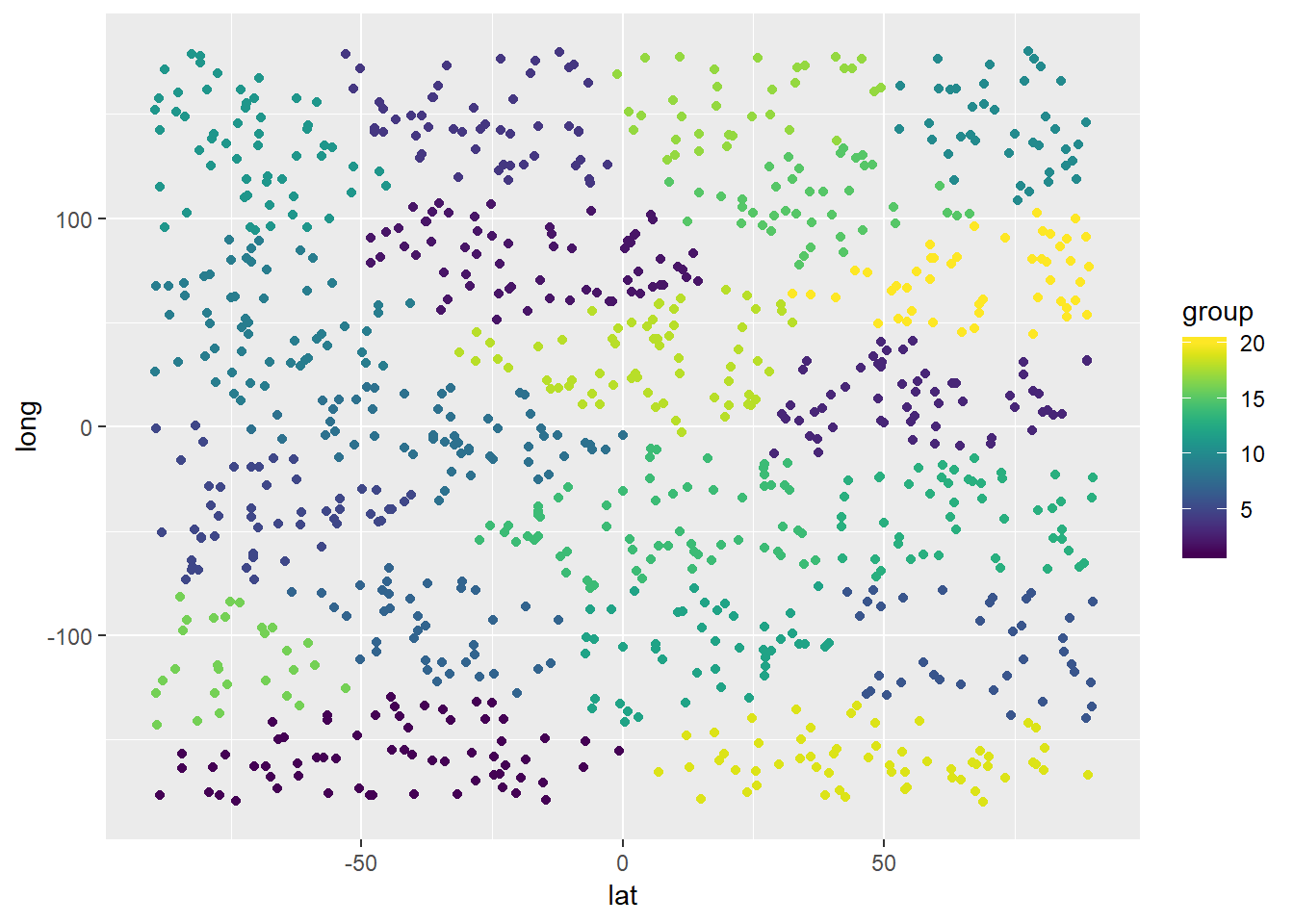
Lassen Sie uns einen weiteren Test mit 20 Warenhäusern durchführen:
cluster_obj <- kmeans(customer_df,centers=customer_df[initial_centers(customer_df,20),])
result_df$group <- cluster_obj$cluster
ggplot(result_df) + geom_point(mapping = aes(x=lat,y=long,color=group)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 
Wenn Sie interessiert sind, lesen Sie meinen Beitrag zur Berechnung des Massenschwerpunkts in R und wie er verwendet werden kann, um ein Lagerstandortproblem in R zu lösen.

Wirtschaftsingenieur mit Interesse an Optimierung, Simulation und mathematischer Modellierung in R, SQL, VBA und Python



Leave a Reply