En esta publicación proporciono un ejemplo de codificación de cómo se puede asignar un grupo de clientes a un almacén cada uno, considerando un conjunto de almacenes fijos con capacidad ilimitada. El supuesto subyacente es que no hay costos fijos y que los costos solo dependen de la distancia euclidiana entre el cliente y el almacén. Además, en este problema no se consideran requisitos de tiempo de entrega ni otras limitaciones relacionadas con el nivel de servicio.
El algoritmo es muy simple y recuerda a los algoritmos de agrupamiento. Recorre todos los clientes y asigna a cada cliente el almacén más cercano, considerando la distancia euclidiana y el sistema de latitud-longitud. A continuación defino este algoritmo como una función:
# función para calcular distancias euclidianas
euclidean_distance <- function(vc,df){
sqrt((as.numeric(rep(vc[1],times=nrow(df)))-df[,1])^2+(as.numeric(rep(vc[2],times=nrow(df)))-df[,2])^2)
}
# función para asignar clientes a almacenes
assignment_algorithm <- function(customers,warehouses){
return_df <- as.data.frame(matrix(nrow=nrow(customers),ncol=3))
colnames(return_df)<-c("lat","long","warehouses")
for(i in 1:nrow(customers)){
return_df[i,] <- c(customers[i,1],customers[i,2],which.min(euclidean_distance(customers[i,],warehouses)))
}
return_df
}Para probar, primero construyo dos conjuntos, con clientes y almacenes ubicados aleatoriamente, respectivamente.
customer_df <- as.data.frame(matrix(nrow=1000,ncol=2))
colnames(customer_df) <- c("lat","long")
warehouse_df <- as.data.frame(matrix(nrow=4,ncol=2))
colnames(warehouse_df) <- c("lat","long")
customer_df[,c(1,2)] <- cbind(runif(n=1000,min=-90,max=90),runif(n=1000,min=-180,max=180))
warehouse_df[,c(1,2)] <- cbind(runif(n=4,min=-90,max=90),runif(n=4,min=-180,max=180))Debajo del encabezado del marco de datos de ubicación del cliente:
head(customer_df)## lat long
## 1 -35.42042 -33.68156
## 2 -50.63025 -64.52526
## 3 43.71663 -36.22302
## 4 -53.30511 135.56315
## 5 -46.32125 84.83210
## 6 83.85849 -60.70374Debajo del encabezado del marco de datos de ubicación de una casa:
head(warehouse_df)## lat long
## 1 -41.007642 118.5673
## 2 81.968627 116.1495
## 3 11.971601 103.5034
## 4 -6.619224 -103.6206Ahora asigno clientes a los almacenes:
# aplicar función
results_df <- assignment_algorithm(customer_df,warehouse_df)
# mostrar el encabezado del resultado
head(results_df)## lat long warehouses
## 1 -35.42042 -33.68156 4
## 2 -50.63025 -64.52526 4
## 3 43.71663 -36.22302 4
## 4 -53.30511 135.56315 1
## 5 -46.32125 84.83210 1
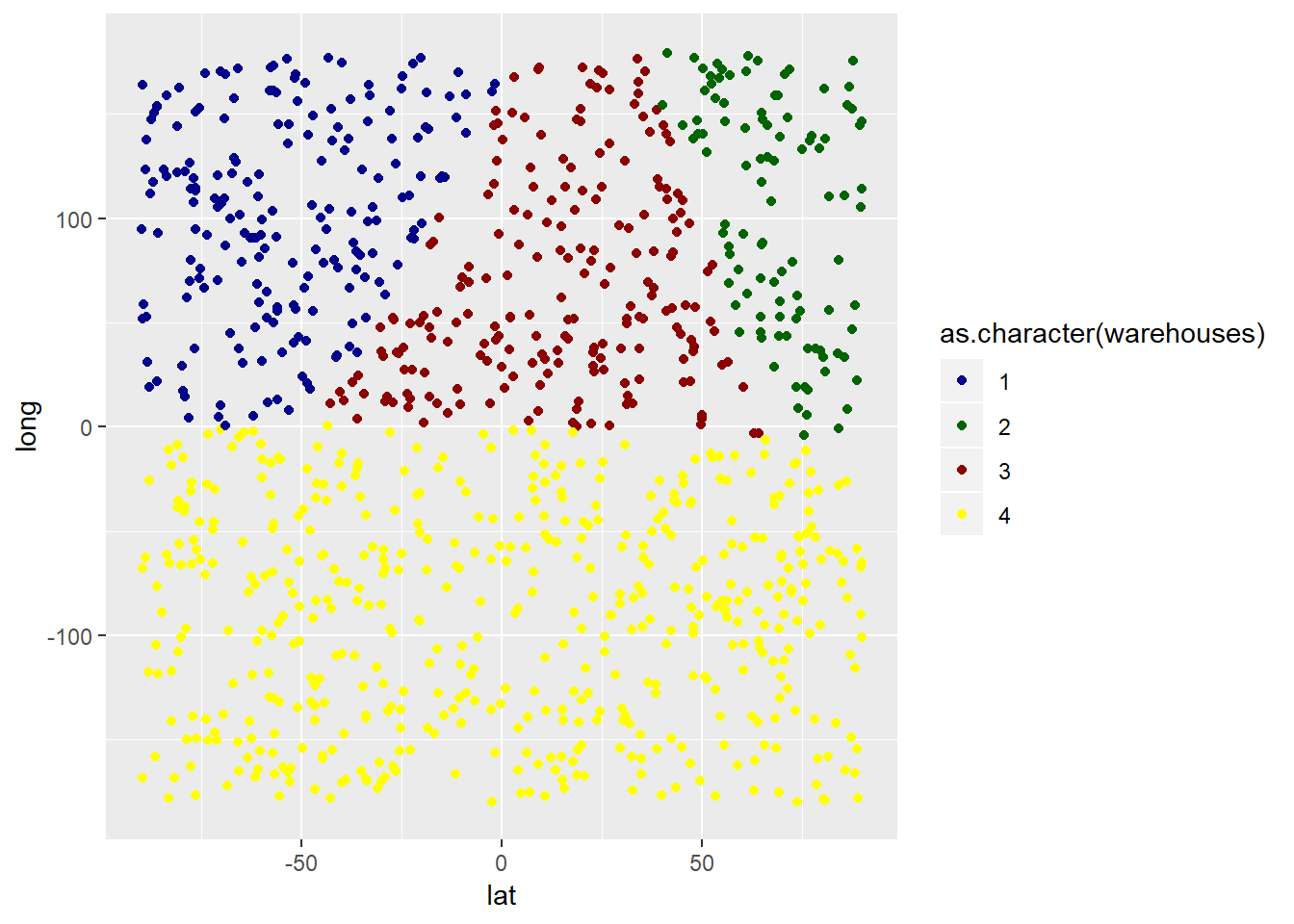
## 6 83.85849 -60.70374 4Además, visualizo los resultados en ggplot2:
library(ggplot2)
ggplot(data = results_df) +
geom_point(mapping = aes(x=lat,y=long,color=as.character(warehouses))) +
scale_color_manual(values=c("darkblue","darkgreen","darkred","yellow")) +
xlim(-90,90) + ylim(-180,180)
Los almacenes se ubican de la siguiente manera:
ggplot(data = warehouse_df) + geom_point(mapping = aes(x=lat,y=long)) + xlim(-90,90) + ylim(-180,180)
En otra publicación muestro cómo ubicar un almacén en el centro de masa, yo en el centro de la demanda del cliente: Problema de un solo almacén – Ubicación del almacén en el centro de masa (cálculo del centro de masa en R) También he escrito publicaciones sobre cómo dividir un grupo de clientes en varios grupos más pequeños, según la proximidad espacial. Este enfoque puede, por ejemplo, utilizarse para ubicar varios almacenes en cada uno de sus centros de masa en R.

Ingeniero industrial especializado en optimización y simulación (R, Python, SQL, VBA)



Leave a Reply