La simulación de Montecarlo es una técnica muy popular cuando se trata de evaluación de riesgos. En publicaciones anteriores, presenté implementaciones de dicha técnica en Python y R (por ejemplo, para evaluar el riesgo asociado con la evolución de los precios de las materias primas y las acciones). También demostré cómo animar simulaciones de Montecarlo en R usando ggplot2 y gganimate.
Editado y traducido el 27 de abril del 2022 por Oswaldo Almonacid
En este artículo implementaré una simulación Montecarlo para evaluar el riesgo de costo -riesgo que el proyecto cueste más de lo presupuestado- para una ubicación de almacén que está siendo considerada por una junta directiva ficticia. Identificaré una ubicación de almacén óptima estimada aplicando el enfoque del centro de masa, y luego usaré la simulación de Montecarlo para evaluar los riesgos de costos asociados con la asignación del almacén en el centro de masa. Es decir, en esta publicación implementaré un flujo de trabajo como el que se ilustra en la figura a continuación.

Ejemplo simplicado de una cadena de suministro con fines de demostración
Con el fin de demostrar la simulación de Montecarlo para la evaluación de riesgos de ubicación de almacenes, consideraré una red de cadena simplificada con suministro directo de los proveedores, un único centro de distribución y entrega directa a los clientes.
El modelo de red descrito se ilustra en la siguiente figura.

Para este ejemplo, considero la cantidad enviada de productos (artículos) como la unidad de medida relevante como variable principal que explica los costos de transporte. Como también explicaré más adelante, según el cliente y los datos disponibles, las unidades de medida relevantes al modelar el impacto en los costos variables de transporte podrían ser, por ejemplo, el peso o el volumen de los envíos, la cantidad de productos enviados o los ingresos por ventas y los gastos de compra.
En este ejemplo, asumiré que los volúmenes de envío son una unidad de medida relevante. Dichos datos estarán disponibles, por ejemplo, al reubicar un almacén existente o al usar y extrapolar datos de redes de distribución ya existentes en otra región con propiedades y carteras de productos similares.
Configuración de datos con ubicaciones artificiales de clientes y proveedores, así como con demanda aleatoria
En el segmento de código a continuación, configuro los datos que contienen las ubicaciones de proveedores y clientes, así como el volumen de envío esperado hacia o desde cada ubicación. Para un análisis del centro de masa (centro de gravedad) de este tipo, la dirección del flujo no es relevante, es decir, no se hace ninguna distinción entre los volúmenes de envío de los proveedores y los clientes. Esto se basa en una fuerte suposición. Es decir, que los precios de envío por unidad de volumen no difieren mucho en el lado de las ventas (hacia los clientes) en comparación con el lado de las compras (de los proveedores). Esta es una premisa significativa que a menudo no se cumplirá.
La razón por la que esta premisa con frecuencia no es totalmente aplicable a los problemas del mundo real es que, por lo general, existen diferencias estructurales en el flujo de material entrante y saliente. Por ejemplo, un centro de distribución podría estar recibiendo envíos entrantes en lotes más grandes, como cargas de contenedores completos.
Sin embargo, los envíos salientes en muchos casos serán más pequeños y, por ejemplo, toman la forma de envíos de paquetería. Si bien los envíos de paquetes y las entregas urgentes a menudo se correlacionan fuertemente con la distancia de transporte, es posible que los contenedores de carga marítima entrantes o la carga ferroviaria no dependan en absoluto de las distancias. En tales casos, debemos ajustar los pesos en uno de los lados (ya sea el lado de las ventas o el lado de las compras). Por ejemplo, es posible que se deba excluir el transporte marítimo de un análisis del centro de gravedad.
No obstante, para este ejemplo supongamos que los volúmenes de envío entrantes y salientes tienen estructuras de costos similares y ambos dependen de la distancia de transporte.
# crear una plantilla vacía de marco de datos
df = as.data.frame(matrix(nrow=1000,ncol=4))
# nombrar encabezados de columnas
colnames(df) = c("longitude",
"latitude",
"volume",
"type")
# los primeros 500 registros son proveedores, los siguientes 500 son clientes
for(i in 1:1000){
if(i > 500){
df$type[i] = "customer"
}else{
df$type[i] = "supplier"
}
df$latitude[i] = rnorm(n=1,
mean = 50,
sd = 1)[1]
df$longitude[i] = rnorm(n=1,
mean=15,
sd=1)[1]
df$volume[i] = rnorm(n=1,
mean=100,
sd=25)[1]
}Una vez ejecutemo dicho código, el marco de datos creado artificialmente debería estar completamente poblado y listo para ser usado. Como habrás notado, definí proveedores y clientes con ubicaciones normalmente distribuidas al azar alrededor de la longitud 50 y la latitud 15. El volumen de envío por proveedor o cliente también sigue una distribución aleatoria.
Por supuesto, los datos del mundo real se verán diferentes, según el caso de uso específico.
Eligiendo una ubicación óptima de almacén usando el enfoque de centro de masa
En una publicación previa, demostré el enfoque del centro de masa como un enfoque de optimización simple para ubicar un almacén en función de su proximidad a los clientes (o proveedores, o ambos). En otras palabras, este es un enfoque heurístico para la asignación óptima de almacenes.
La siguiente imagen ilustra cómo el centro de masa se deriva de los objetos. Estos objetos pueden ser objetos físicos o elementos abstractos, como la demanda del cliente. La masa, en este caso, representa la demanda del respectivo cliente.

Como se ilustra en la figura a continuación, el centro de masa o centro de gravedad cambia cuando hay un cambio en los pesos basados en la ubicación (gravedad).

El enfoque del centro de masa se basa en algunos supuestos simplificadores. Estos supuestos son los siguientes:
- Los costos de transporte por envío se correlacionan fuertemente con la distancia de transporte
- Se asume que la correlación es lineal
- La distancia de transporte se puede aproximar con normas de distancia euclidianas, es decir, líneas rectas
- Cualquier diferencia estructural en las clases de envío, por ejemplo, envío prioritario versus envío económico, se puede ajustar con los factores de ponderación relativos basados en categorías
El centro de masa también suele denominarse centro de gravedad. El enfoque también está bien explicado con fórmulas. Aquí muestro la fórmula para calcular la coordenada x promedio ponderada del centro de gravedad (siendo x la longitud).

De la misma manera, puedo expresar la coordenada y promedio ponderada del centro de masa (latitud) con la misma fórmula:

Estas fórmulas calculan, como se indicó, las coordenadas x e y promedio ponderadas del centro de masa, respectivamente. La definición de pesos puede, por ejemplo, basarse en la cantidad de unidades enviadas, la cantidad de ingresos por ventas y gastos de compra, o los equivalentes de peso que a ser enviados. Dependiendo de los datos disponibles del cliente que se somete a un análisis de asignación de almacén de este tipo, una de estas definiciones de peso será la más adecuada para elegir.
En las siguientes líneas de código, derivo el centro de masa, que representa la ubicación óptima del almacén en este ejemplo. En otras palabras, implemento las dos fórmulas para calcular las coordenadas x e y promedio ponderadas por la demanda de ventas y la cantidad de suministro de origen (proveedores) y la cantidad de demanda de destino (clientes). El eje x será la longitud, y el eje y será la latitud.
# función que deriva el centro de mesa y retorna un vector con dos entradas
# retorna valor no. 1: coordenada de longitud del centro de masa
# retorna valor no. 2: coordenada de latitud del centro de masa
center_of_mass = function(df){
longitude = sum(df$volume*df$longitude)/sum(df$volume)
latitude = sum(df$volume*df$latitude)/sum(df$volume)
return(c(as.numeric(longitude),as.numeric(latitude)))
}Habiendo implementado las fórmulas en forma de funciones en R, ahora las aplico para derivar el centro de masa para este ejemplo:
# aplicar la función de cálculo del centro de masa
com = center_of_mass(df)Agrego el centro de masa derivado al marco de datos general. Este marco de datos se usará más tarde como entrada para visualizaciones basadas en ggplot2:
# agregar una fila más con el centro de masa como entrada separada
df[1001,] = c(com[1],
com[2],
200.0, # para agrandar este punto en el scatterplot de ggplot2
"CoM") # significa "Center of Mass" (centro de masa)
# asegurar que todas las columnas numéricas son realmente numéricas
df$latitude = as.numeric(df$latitude)
df$longitude = as.numeric(df$longitude)
df$volume = as.numeric(df$volume)Visualización de la ubicación óptima del almacén en función del enfoque del centro de masa
Se puede visualizar el centro de masa, es decir, la ubicación óptima sugerida del almacén, mediante un gráfico de dispersión ggplot2.
# importar ggplot2 para visualización de gráfico de dispersión
library(ggplot2)
# mostrar el centro de gravedad usando el gráfico de dispersión
plot = ggplot() +
geom_point(data = df[-1001,], mapping = aes(x = longitude,
y = latitude,
color = type,
size = volume),alpha=0.05) +
geom_point(data=df[1001,],
mapping = aes(x=longitude,
y=latitude,
color=type,
size=volume)) +
scale_color_manual(values=c("black","red","blue")) +
xlab("Longitude") +
ylab("Latitude") +
ggtitle("Visualización del centro de masa con ggplot2 scatter plot") +
labs(color = "Tipo",
size = "Volumen de envío")
# mostrar el gráfico
plot
También se puede visualizar la distribución en un mapa usando ggmap. A continuación se muestra el gráfico de puntos que creé usando ggmap en R (un marco basado en ggplot2 para el trazado basado en mapas).
# Cargar librería ggmap
library(ggmap)
# Visualizar el gráfico de dispersión usando ggmap
mapObj = get_stamenmap(
bbox = c(left = 5,
bottom = 45,
right = 25,
top = 55),
maptype = "toner-background",
zoom = 4)
mapatt = attributes(mapObj)
mapObj = matrix(adjustcolor(mapObj, alpha.f = 0.2), nrow = nrow(mapObj))
attributes(mapObj) = mapatt
mapObj = ggmap(mapObj)
mapObj = mapObj +
geom_point(data = df[-1001,], mapping = aes(x = longitude,
y = latitude,
color = type,
size = volume),alpha=0.05) +
geom_point(data=df[1001,],
mapping = aes(x=longitude,
y=latitude,
color=type,
size=volume)) +
scale_color_manual(values=c("black","red","blue")) +
xlab("Longitude") +
ylab("Latitude") +
ggtitle("Visualización del centro de masa con ggmap point plot") +
labs(color = "Tipo",
size = "Volumen de envío")
mapObj
Las diferencias en color podrían crear confusión sobre la visualización y la densidad del volumen. Para resolver este punto, podemos considerar un gráfico con clientes y proveedores del mismo color.
# Visualizar el gráfico de dispersión usando ggmap
mapObj = get_stamenmap(
bbox = c(left = 5,
bottom = 45,
right = 25,
top = 55),
maptype = "toner-background",
zoom = 4)
mapatt = attributes(mapObj)
mapObj = matrix(adjustcolor(mapObj, alpha.f = 0.2), nrow = nrow(mapObj))
attributes(mapObj) = mapatt
mapObj = ggmap(mapObj)
mapObj = mapObj +
geom_point(data = df[-1001,], mapping = aes(x = longitude,
y = latitude,
color = type,
size = volume),alpha=0.03) +
geom_point(data=df[1001,],
mapping = aes(x=longitude,
y=latitude,
color=type,
size=volume)) +
scale_color_manual(values=c("black","red","red")) +
xlab("Longitude") +
ylab("Latitude") +
ggtitle("Visualización de centro de masa con ggmap point plot") +
labs(color = "Tipo",
size = "Volumen de envío")
mapObj
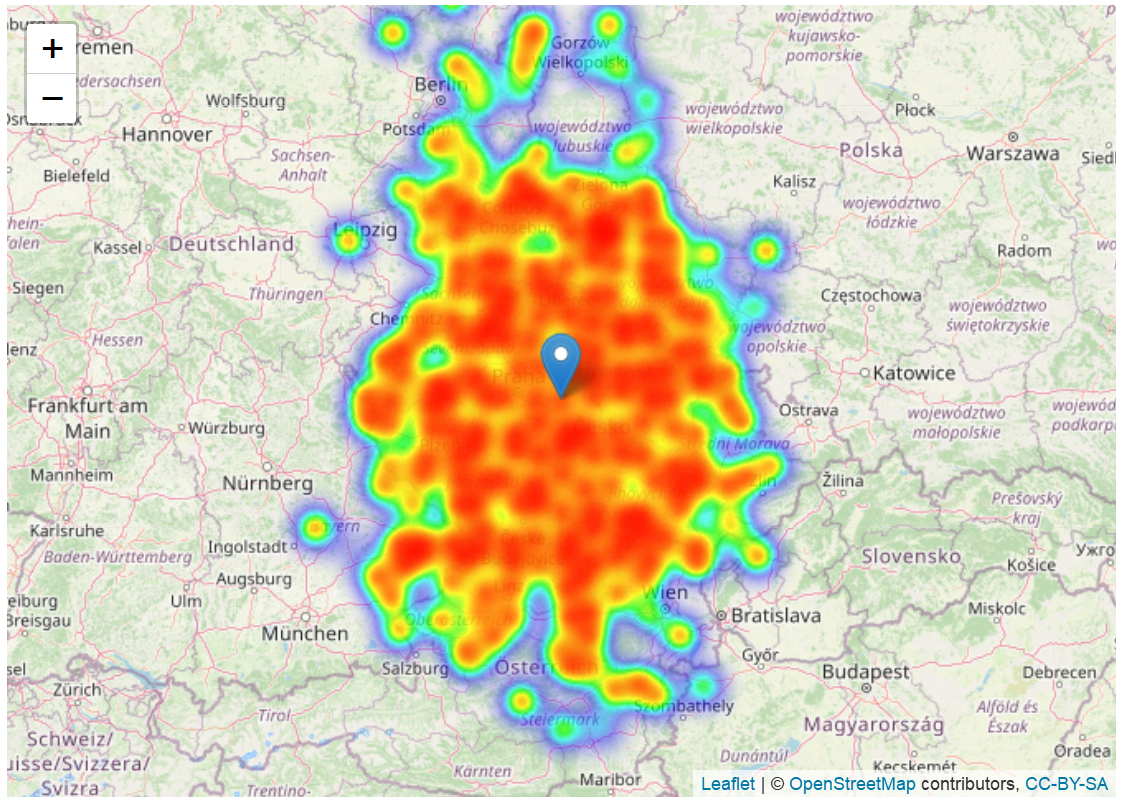
Otro enfoque de visualización sería usar el paquete leaflet en R para graficar mapas de calor de la distribución del volumen de envío de mapas, y agregar un marcador en el centro de masa. Este proceso se realiza con las siguientes líneas de código (el paquete leaflet utiliza Leaflet.js).
# importar leaflet and leaflet.extras para graficar un mapa de calor
library(leaflet)
library(leaflet.extras)
library(magrittr)
# definir el centro del mapa
lat_center = df$latitude[1001]
long_center = df$longitude[1001]
# crear el mapa de calor
heatmap = df %>%
leaflet() %>%
addTiles() %>%
setView(long_center,lat_center,6.15) %>%
addHeatmap(lng=~longitude,lat=~latitude,intensity=~volume,max=100,radius=13,blur=20) %>%
addMarkers(lng=as.numeric(com[1]),lat=as.numeric(com[2]))
# mostrar el mapa de calor con el centro de gravedad
heatmap
Cálculo de los costes de transporte en función de la distancia euclidiana y el volumen de envío
Procederé a implementar una función en R que calcule todos los costos de transporte esperados basados en un ejemplo simplicado donde multiplico la distancia euclidiana por el volumen de envío. En problemas del mundo real, se podría, por ejemplo, considerar un enfoque zonificado (por ejemplo, FedEx basa sus precios de envío de paquetes en zonas).
Nota: la distancia euclidiana es la longitud de una línea recta entre dos puntos en un plano de dos dimensiones. A continuación se muestra la implementación de la función de costo a medida.
# función ayuda para calcular la distancia euclideana
euclidean_distance = function(longitude,latitude,long_com,lat_com){
long_distances = (longitude-long_com[1])^2
lat_distances = (latitude-lat_com[1])^2
return((long_distances+lat_distances)*0.5)
}
# función para calcular los costos de transporte
transport_costs = function(df){
long_com = df$longitude[nrow(df)]
lat_com = df$latitude[nrow(df)]
euclideans = euclidean_distance(df$latitude[-nrow(df)],df$latitude[-nrow(df)],long_com,lat_com)
costs = euclideans*df$volume[-nrow(df)]
return(sum(costs))
}Ahora aplicaré la función de cálculo de costos de transporte para ver la suma total de los costos de transporte esperados para el almacén ubicado en el centro de masa. Los costos están expresando en millones.
transport_costs(df)/1000000
## [1] 60.8644Aplicación de la simulación Montecarlo para evaluar los costos y riesgos asociados a la ubicación del almacén elegido
Los datos, especialmente los datos de oferta y demanda, están sujetos a volatilidad, estacionalidad e incertidumbre. La simulación de Montecarlo, una de las técnicas populares utilizadas por profesionales en supply chain analytics, es un método apropiado para la evaluación de riesgos.
En este caso, existe el riesgo de seleccionar una ubicación para un nuevo almacén. ¿Qué tan sensibles son los costos de transporte si elegimos esta ubicación? ¿En cuánto se podrían incrementar los costos de transporte, en comparación con los costos de transporte calculados anteriormente?
Podemos usar una simulación de Montecarlo aplicando la repetición del experimento, con distribuciones normales a los volúmenes de envío por cliente y proveedor. Repetiré el escenario de oferta y demanda (es decir, la distribución de los volúmenes de envío) 1,000 veces. Para cada ejecución, calcularé los costos de transporte resultantes y almacenaré el resultado de cada ejecución en una tabla de datos.
# crear tabla de datos para almacenar los resultados de la simulación de Montecarlo
results = as.data.frame(matrix(nrow=10000,ncol=2))
colnames(results) = c("iteration","costs")
# ejecutar 10,000 iteraciones de la simulación de Montecarlo para evaluar la sensibilidad de costo
for(i in 1:10000){
df$volume[-1001] = rnorm(n=1000,
mean=100,
sd=25)
results$iteration[i] = i
results$costs[i] = transport_costs(df)/1000000
}
# Graficar histograma con los resultados de la simulación de Montecarlo
ggplot() + geom_histogram(data = results,
mapping = aes(x=costs),
fill = "red",
bins = 25) +
ggtitle("Sensibilidad de costos de transporte simulados en el centro de gravedad (centro de masa)
)") +
xlab("Costos de transporte simulados") +
ylab("Frecuencia absoluta")
Esto completa mi ejemplo sobre cómo aplicar la simulación de Montecarlo para la evaluación de la sensibilidad y el riesgo de costos de asignación de almacenes.
En otras publicaciones hemos mostrados cómo se puede, por ejemplo, animar corridas de simulaciones de Montecarlo con gganimate en R, o visualizar la distribución de la demanda espacial en Python con paquetes como leaflet, o en R con paquetes como deckgl.

Ingeniero industrial especializado en optimización y simulación (R, Python, SQL, VBA)



Leave a Reply