En una publicación anterior, mostré cómo se puede abordar un problema de ubicación de un solo almacén ubicando el almacén cerca de su centro de masa. En este post queremos ubicar varios almacenes en su centro de masa.
Usaremos las funciones ya definidas en posts anteriores.
En http://www.supplychaindataanalytics.com/single-warehouse-problem-locating-warehouse-at-center-of-mass-using-r/ proporcioné una función para ubicar un solo almacén en su centro de masa.
En http://www.supplychaindataanalytics.com/proximity-based-spatial-customer-grouping-in-r, mostré cómo agrupar clientes en función de la agrupación en clústeres de proximidad espacial.
# ejemplo ver aquí: http://www.supplychaindataanalytics.com/single-warehouse-problem-locating-warehouse-at-center-of-mass-using-r/
center_of_mass <- function(x,y,w){
c(crossprod(x,w)/sum(w),crossprod(y,w)/sum(w))
}
# ejemplo ver aquí: http://www.supplychaindataanalytics.com/proximity-based-spatial-customer-grouping-in-r
initial_centers <- function(customers,centers){
quantiles <- c()
for(i in 1:centers){
quantiles <- c(quantiles,i*as.integer(nrow(customers)/centers))
}
quantiles
}Combinaremos estos dos enfoques para resolver un problema de ubicación de varios almacenes utilizando la teoría del centro de masa. Este enfoque es aplicable cuando ya sabemos cuántos almacenes queremos operar. El planteamiento en el puesto que nos ocupa no será suficiente para solucionar un problema en el que aún no sabemos cuántos almacenes queremos realmente operar.
Empiezo creando un marco de datos con 1000 clientes distribuidos aleatoriamente con demanda distribuida aleatoriamente.
customer_df <- as.data.frame(matrix(nrow=1000,ncol=3))
colnames(customer_df) <- c("lat","long","demand")
customer_df$lat <- runif(n=1000,min=-90,max=90)
customer_df$long <- runif(n=1000,min=-180,max=180)
customer_df$demand <- runif(n=1000,min=0,max=10)
head(customer_df)## lat long demand
## 1 -42.50378 137.62188 9.608067
## 2 47.79308 101.30536 9.510299
## 3 -14.17326 24.38595 1.610305
## 4 -85.34352 -151.29061 6.394425
## 5 -26.31244 112.75030 6.972434
## 6 55.01428 58.17198 2.797564A continuación, agrupo a los clientes utilizando el enfoque mostrado en una publicación anterior y aplicando la función definida initial_centers. Quiero ubicar 20 almacenes, así que agrupo a los clientes en 20 grupos.
centeroids <- initial_centers(customer_df[,-3],20)
cluster_obj <- kmeans(customer_df[,-3],centers = customer_df[centeroids,-3])
customer_df$group <- cluster_obj$cluster
head(customer_df)## lat long demand group
## 1 -42.50378 137.62188 9.608067 2
## 2 47.79308 101.30536 9.510299 4
## 3 -14.17326 24.38595 1.610305 6
## 4 -85.34352 -151.29061 6.394425 8
## 5 -26.31244 112.75030 6.972434 18
## 6 55.01428 58.17198 2.797564 16Como se muestra arriba, agregué el índice de grupo basado en clústeres al marco de datos del cliente.
Ahora, definiré una función que recorrerá cada grupo de clientes e identificará el centro de masa. El requisito es que se debe ingresar un marco de datos, que contenga una columna de latitud, longitud, demanda y grupo, exactamente en este formato:
multiple_centers_of_mass <- function(df){
result_df <- as.data.frame(matrix(nrow=nrow(df),ncol=6))
colnames(result_df) <- c("lat","long","demand","group","com_lat","com_long")
result_df[,c(1,2,3,4)] <- df
for(i in 1:length(unique(df[,4]))){
sub_df <- result_df[result_df$group==i,]
com <- center_of_mass(sub_df$lat,sub_df$long,sub_df$demand)
result_df$com_lat[result_df$group==i] <- com[1]
result_df$com_long[result_df$group==i] <- com[2]
}
result_df
}Probemos la función multiple_centers_of_mass que acabo de definir:
com_df <- multiple_centers_of_mass(customer_df)
head(com_df)## lat long demand group com_lat com_long
## 1 -42.50378 137.62188 9.608067 2 -25.97973 158.17382
## 2 47.79308 101.30536 9.510299 4 63.58158 84.91329
## 3 -14.17326 24.38595 1.610305 6 -21.20417 26.80993
## 4 -85.34352 -151.29061 6.394425 8 -64.12072 -145.48419
## 5 -26.31244 112.75030 6.972434 18 -33.15564 99.15738
## 6 55.01428 58.17198 2.797564 16 35.04988 44.42388Visualicemos los resultados de la prueba usando un diagrama de dispersión del paquete ggplot2 R. A continuación, verá las ubicaciones de los almacenes (centros de masa):
library(ggplot2)
lat_wh_vc <- unique(com_df$com_lat)
long_wh_vc <- unique(com_df$com_long)
warehouse_df <- as.data.frame(matrix(nrow=length(lat_wh_vc),ncol=2))
warehouse_df[,1] <- lat_wh_vc
warehouse_df[,2] <- long_wh_vc
colnames(warehouse_df) <- c("lat","long")
ggplot(warehouse_df) + geom_point(mapping = aes(x=lat,y=long)) + xlim(-90,90) + ylim(-180,180)
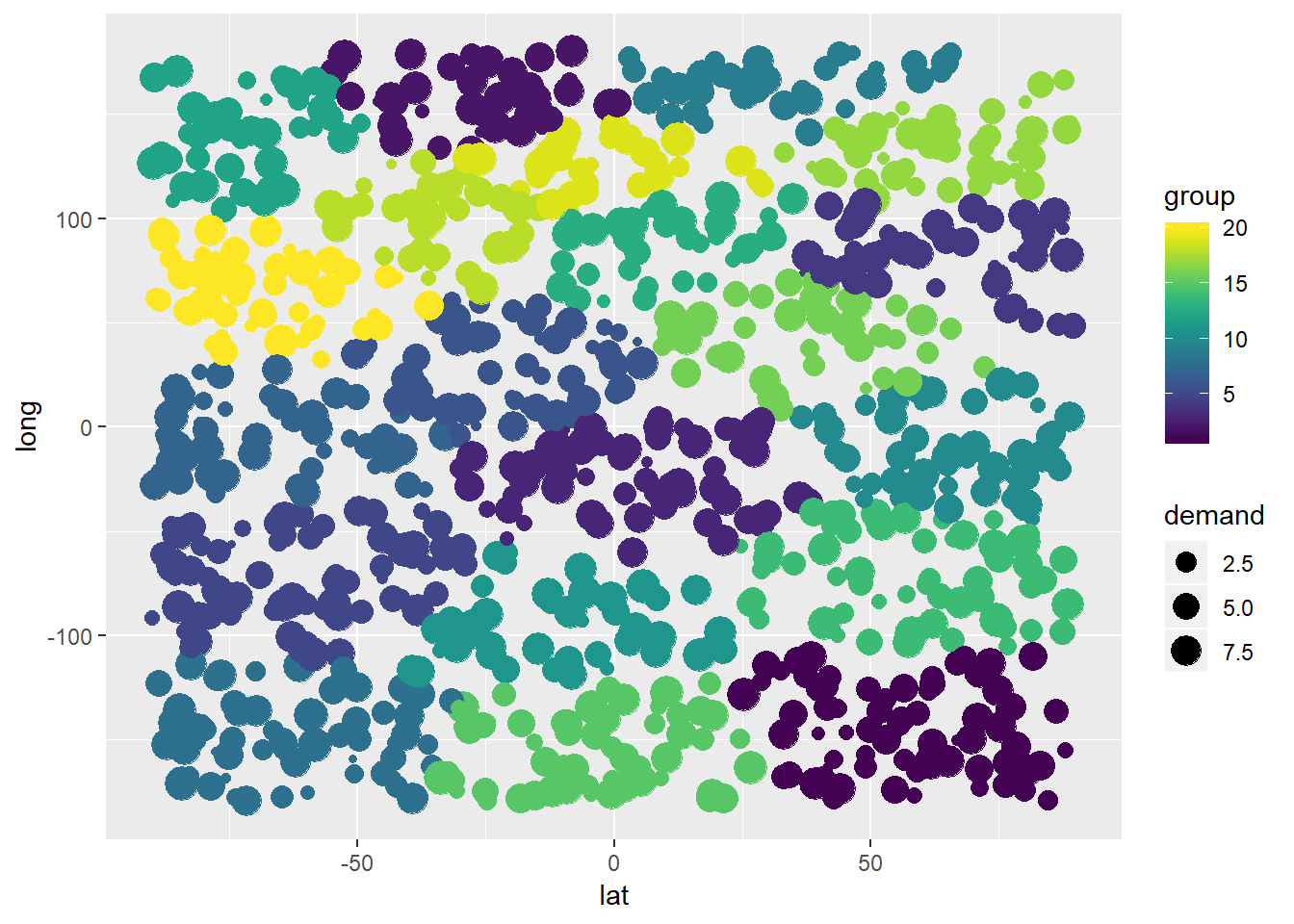
Los clientes se agrupan como se muestra a continuación:
library(viridis)## Advertencia: el paquete 'viridis' se creó con la versión 3.5.3 de R## Cargando el paquete requerido: viridisLiteggplot(com_df) + geom_point(mapping = aes(x=lat,y=long,color=group,size=demand)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 

Ingeniero industrial especializado en optimización y simulación (R, Python, SQL, VBA)



Leave a Reply