이전 게시물에서 CAGR 기반 예측에 대해 설명했습니다. CAGR 기반 예측은 판매 및 생산량 예측과 같이 업계에서 자주 적용되는 매우 간단한 예측 방법입니다.
간단한 예측 모델에는 이점이 있습니다. 이해하기 쉽고 구현하기 쉽습니다. 또한 매개 변수가 거의 없으므로 핵심 가정이 매우 정확합니다. 이런 식으로 간단한 예측 방법이 많은 경우에 가장 좋은 예측 방법이라고 말할 수 있습니다. 즉, 미래를 예측하려는 경우 완전히 이해하고 언제든지 누구에게나 설명할 수 있는 예측 모델을 사용하는 것이 좋습니다.
이 게시물에서는 간단한 이동 평균 계산을 기반으로 하는 시계열 예측을 소개하려고 합니다. 롤링 평균 또는 롤링 평균이라고도 하는 이동 평균은 과거 시계열 데이터를 분석하고 전처리하는 데 사용됩니다. 그럼에도 불구하고 간단한 예측 알고리즘을 만드는 데 사용할 수 있습니다.
단순 이동 평균 예측을 두 가지 범주로 구분합니다.
(a) 롤링 평균을 계산하여 과거 데이터에서 예측
(b) (a)와 동일하지만 추가 고유 성장 매개변수가 있음
따라서 범주 (b)는 CAGR 기반 예측과 롤링 평균 예측의 조합입니다.
CAGR 기반 예측과 마찬가지로 단순 이동 평균 예측은 제한 시간 지평에만 사용할 수 있습니다.
정의된 길이의 이동 평균을 계산하는 함수를 사용하여 아래 코딩 예제에서 이러한 예측 접근 방식을 구현합니다. 이 기능을 R로 구현하고 미래 가치 예측에 적용합니다. 저는 이 함수를 “sma_forecast”라고 부릅니다. 아래 R 코드에서 구현됩니다.
sma_forecast = function(past,length){
future = rep(0,times = length)
prediction = c(past,future)
for(i in (length(past)+1):length(prediction)){
prediction[i] = mean(prediction[(i-length(past)):(i-1)])
}
return(prediction)
}이 워크플로의 다음 단계는 기록 데이터를 읽는 것입니다. 이 경우 특정 국가 내에서 특정 연도에 생산된 단위 수로 측정된 coutry별 자동차 산업의 연간 생산량 데이터를 읽었습니다. 마지막 단계는 sma_forecast를 사용하여 예측을 계산하는 것입니다. 이 모든 작업은 R을 사용하여 아래의 코딩 예제에서 수행됩니다.
library(readxl)
data_df = as.data.frame(read_xls("oica.xls"))
head(data_df)## year country total
## 1 2018 Argentina 466649
## 2 2018 Austria 164900
## 3 2018 Belgium 308493
## 4 2018 Brazil 2879809
## 5 2018 Canada 2020840
## 6 2018 China 27809196tail(data_df)## year country total
## 835 1999 Turkey 297862
## 836 1999 Ukraine 1918
## 837 1999 UK 1973519
## 838 1999 USA 13024978
## 839 1999 Uzbekistan 44433
## 840 1999 Others 11965library(dplyr)
data_df = filter(data_df,country=="USA")
library(ggplot2)
ggplot(data_df) +
geom_path(mapping = aes(x = year, y = total/1000000),
size = 2,
color = "red") +
labs(title = "US automotive industry production output",
subtitle = "historical OICA data, for 1999 - 2018") +
xlab("year") +
ylab("output [millions of units]") +
ylim(0,15)
library(dplyr)
data_df = data_df %>% arrange(desc(-year))
predictionVals = sma_forecast(past=data_df$total,length = 10)
plot_df = as.data.frame(matrix(nrow=length(predictionVals),ncol= 4))
colnames(plot_df) = c("year","country","total","category")
plot_df$total = predictionVals
plot_df$category[1:nrow(data_df)] = "history"
plot_df$category[(nrow(data_df)+1):length(predictionVals)] = "prediction"
plot_df$year = data_df$year[1]:(data_df$year[1]+length(predictionVals)-1)
plot_df$country = data_df$country[1]
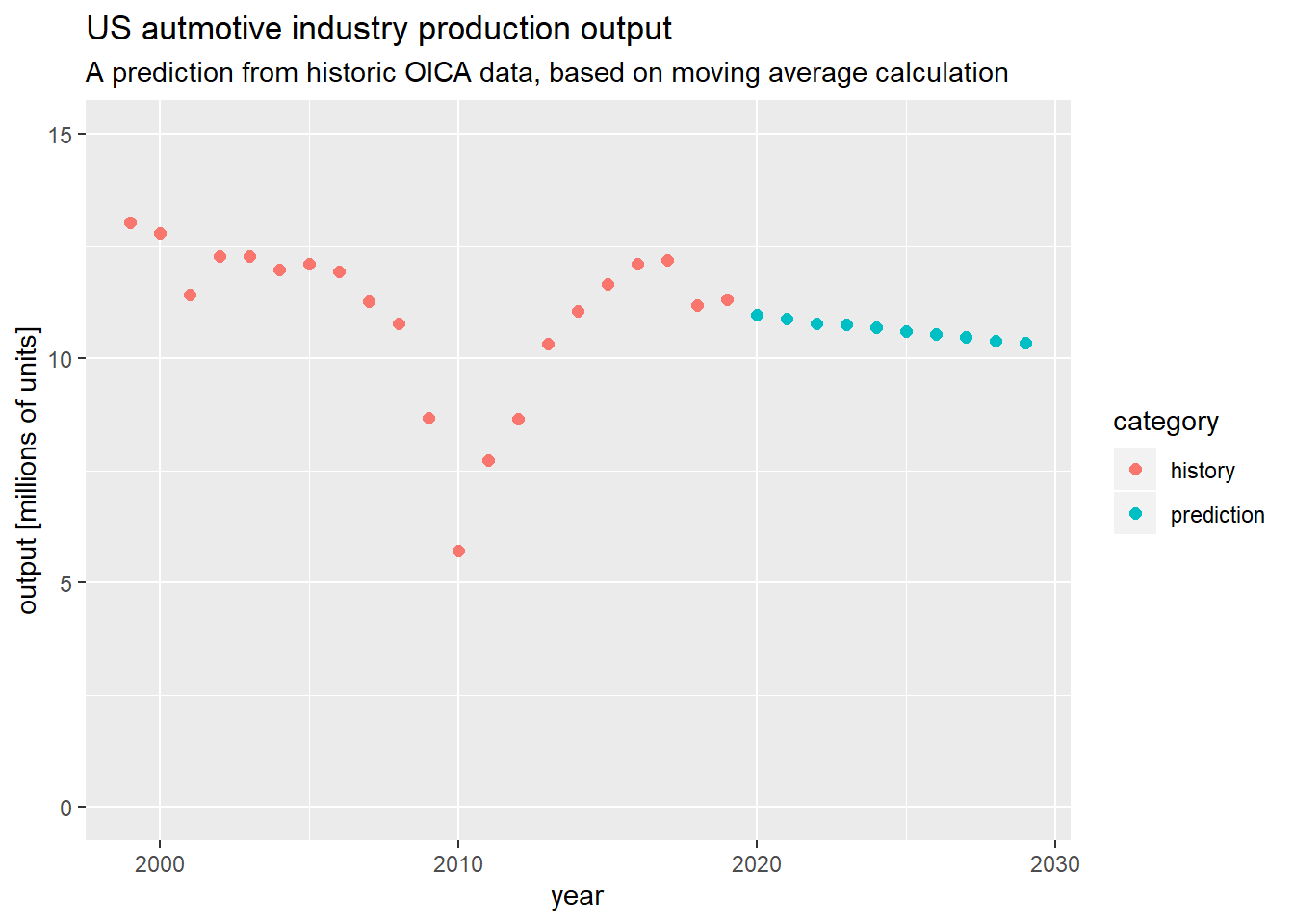
ggplot(plot_df) +
geom_point(mapping = aes(x = year,
y = total/1000000,
color = category),
size = 2) +
labs(title = "US autmotive industry production output",
subtitle = "A prediction from historic OICA data, based on moving average calculation") +
xlab("year") +
ylab("output [millions of units]") +
ylim(0,15)
이 시점에서 내 예를 마칩니다.
내가 추가할 수 있었던 것들:
(a) 방법을 평가하기 위한 교육 및 테스트 세트 분할
(b) 다양한 국가, 시간 간격 및 예측 길이에 대한 평가 방법
(c) 생산 출력 데이터와 다른 데이터에 대한 테스트 예측
(라) …
이 게시물이 흥미로웠다면 예를 들어 CAGR 기반 예측, OICA 데이터 획득 및 분석, 시계열 분석, 선형 프로그래밍, 자동차 산업 판매 데이터의 공개 소스 등과 같은 다른 게시물을 확인하는 것이 좋습니다.

최적화 및 시뮬레이션을 전문으로하는 산업 엔지니어 (R, Python, SQL, VBA)



Leave a Reply