이전 게시물에서 저는 창고를 질량 중심 근처에 배치하여 단일 창고 위치 문제에 어떻게 접근 할 수 있는지 보여주었습니다. 이 게시물에서는 질량 중심에 여러 창고를 배치하려고합니다. 이전 게시물에서 이미 정의 된 기능을 사용합니다. http://www.supplychaindataanalytics.com/single-warehouse-problem-locating-warehouse-at-center-of-mass-using-r/에서 질량 중심에서 단일 창고를 찾는 기능을 제공했습니다. http://www.supplychaindataanalytics.com/proximity-based-spatial-customer-grouping-in-r에서 공간 근접 클러스터링을 기반으로 고객을 그룹화하는 방법을 보여주었습니다.
# 예제는 다음을 참조하십시오 : http://www.supplychaindataanalytics.com/single-warehouse-problem-locating-warehouse-at-center-of-mass-using-r/
center_of_mass <- function(x,y,w){
c(crossprod(x,w)/sum(w),crossprod(y,w)/sum(w))
}
# 예제는 여기를 참조하십시오 : http://www.supplychaindataanalytics.com/proximity-based-spatial-customer-grouping-in-r
initial_centers <- function(customers,centers){
quantiles <- c()
for(i in 1:centers){
quantiles <- c(quantiles,i*as.integer(nrow(customers)/centers))
}
quantiles
}질량 중심 이론을 사용하여 다중 창고 위치 문제를 해결하기 위해이 두 가지 접근 방식을 결합 할 것입니다. 이 접근 방식은 우리가 운영하려는 창고의 수를 이미 알고있는 경우에 적용 할 수 있습니다. 당면한 포스트의 접근 방식은 우리가 실제로 운영하고자하는 창고의 수를 아직 알지 못하는 문제를 해결하는 데 충분하지 않을 것입니다. 무작위로 분산 된 수요를 가진 1000 명의 무작위로 분산 된 고객으로 데이터 프레임을 생성하는 것부터 시작합니다.
customer_df <- as.data.frame(matrix(nrow=1000,ncol=3))
colnames(customer_df) <- c("lat","long","demand")
customer_df$lat <- runif(n=1000,min=-90,max=90)
customer_df$long <- runif(n=1000,min=-180,max=180)
customer_df$demand <- runif(n=1000,min=0,max=10)
head(customer_df)## lat long demand
## 1 -42.50378 137.62188 9.608067
## 2 47.79308 101.30536 9.510299
## 3 -14.17326 24.38595 1.610305
## 4 -85.34352 -151.29061 6.394425
## 5 -26.31244 112.75030 6.972434
## 6 55.01428 58.17198 2.797564다음으로, 이전 게시물에 표시된 접근 방식을 사용하고 정의 된 함수 initial_centers를 적용하여 고객을 그룹화합니다. 20 개의 창고를 찾고 싶어서 고객을 20 개의 그룹으로 묶습니다.
centeroids <- initial_centers(customer_df[,-3],20)
cluster_obj <- kmeans(customer_df[,-3],centers = customer_df[centeroids,-3])
customer_df$group <- cluster_obj$cluster
head(customer_df)## lat long demand group
## 1 -42.50378 137.62188 9.608067 2
## 2 47.79308 101.30536 9.510299 4
## 3 -14.17326 24.38595 1.610305 6
## 4 -85.34352 -151.29061 6.394425 8
## 5 -26.31244 112.75030 6.972434 18
## 6 55.01428 58.17198 2.797564 16위에 표시된 것처럼 클러스터링 기반 그룹 인덱스를 고객 데이터 프레임에 추가했습니다. 이제 모든 고객 그룹을 반복하고 질량 중심을 식별하는 기능을 정의합니다. 요구 사항은 위도, 경도, 수요 및 그룹 열을 포함하는 데이터 프레임을 정확히 다음 형식으로 입력해야한다는 것입니다.
multiple_centers_of_mass <- function(df){
result_df <- as.data.frame(matrix(nrow=nrow(df),ncol=6))
colnames(result_df) <- c("lat","long","demand","group","com_lat","com_long")
result_df[,c(1,2,3,4)] <- df
for(i in 1:length(unique(df[,4]))){
sub_df <- result_df[result_df$group==i,]
com <- center_of_mass(sub_df$lat,sub_df$long,sub_df$demand)
result_df$com_lat[result_df$group==i] <- com[1]
result_df$com_long[result_df$group==i] <- com[2]
}
result_df
}방금 정의한 multiple_centers_of_mass 함수를 테스트 해 보겠습니다.
com_df <- multiple_centers_of_mass(customer_df)
head(com_df)## lat long demand group com_lat com_long
## 1 -42.50378 137.62188 9.608067 2 -25.97973 158.17382
## 2 47.79308 101.30536 9.510299 4 63.58158 84.91329
## 3 -14.17326 24.38595 1.610305 6 -21.20417 26.80993
## 4 -85.34352 -151.29061 6.394425 8 -64.12072 -145.48419
## 5 -26.31244 112.75030 6.972434 18 -33.15564 99.15738
## 6 55.01428 58.17198 2.797564 16 35.04988 44.42388ggplot2 R 패키지의 산점도를 사용하여 테스트 결과를 시각화 할 수 있습니다. 아래에서 창고 위치 (질량 중심)를 볼 수 있습니다.
library(ggplot2)
lat_wh_vc <- unique(com_df$com_lat)
long_wh_vc <- unique(com_df$com_long)
warehouse_df <- as.data.frame(matrix(nrow=length(lat_wh_vc),ncol=2))
warehouse_df[,1] <- lat_wh_vc
warehouse_df[,2] <- long_wh_vc
colnames(warehouse_df) <- c("lat","long")
ggplot(warehouse_df) + geom_point(mapping = aes(x=lat,y=long)) + xlim(-90,90) + ylim(-180,180)
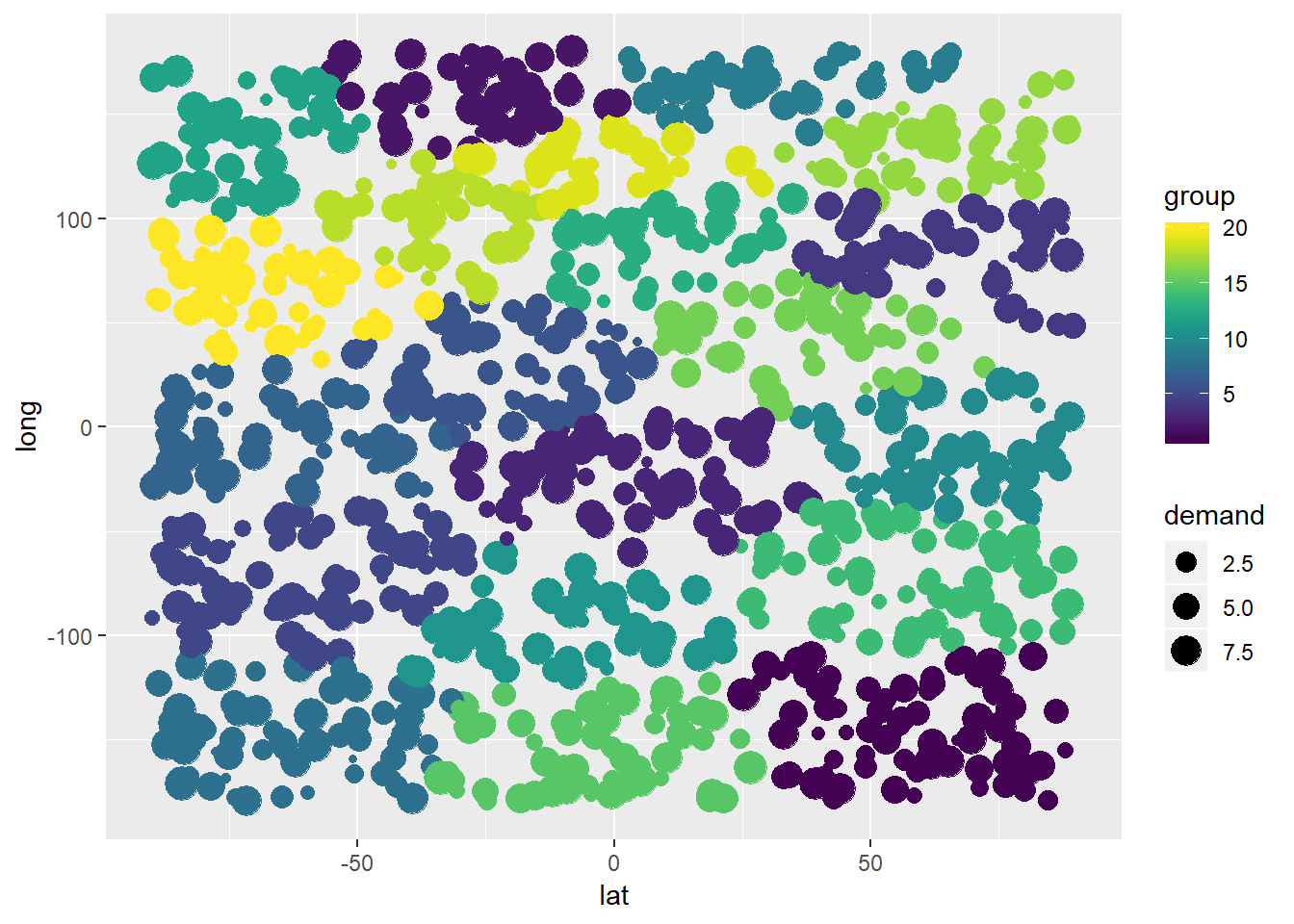
고객은 아래와 같이 그룹화됩니다.
library(viridis)## 경고 : 'viridis'패키지는 R 버전 3.5.3에서 빌드되었습니다.## 필수 패키지로드 : viridisLiteggplot(com_df) + geom_point(mapping = aes(x=lat,y=long,color=group,size=demand)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 

최적화 및 시뮬레이션을 전문으로하는 산업 엔지니어 (R, Python, SQL, VBA)



Leave a Reply