이전 게시물에서 예를 들어 주가 데이터를 쿼리하는 방법을 보여주었습니다. Python의 pandas_datareader.
이 게시물에서는 고려할 수있는 주식 세트를 기반으로 효율적인 포트폴리오를 구성 할 수있는 알고리즘을 제시합니다. 알고리즘은 자신이 감수한다고 느끼는 위험 수준에 따라 포트폴리오에있는 각 주식의 최적 점유율을 결정합니다.
보다 정확하게는 특정 주식 세트로 구성된 포트폴리오의 효율적인 경계를 시각화하는 방법을 제시 할 것입니다. 이 예에서는 모두 트럭 운송 회사 인 다음 8 개의 주식에 대해 작업합니다.
- Yamato Holdings (YATRY)
- Knight-Swift Transportation Holdings (KNX)
- BEST (BEST)
- YRC Worldwide (YRCW)
- Schneider National (SNDR)
- Old Dominion Freight Line (ODFL)
- Arc Best (ARCB)
- Werner Enterprises (WERN)
위험은 과거 수익률의 표준 편차로 측정됩니다. 수익률은 평균 과거 일일 주식 수익률로 측정됩니다 (종가 사용).
먼저 Python에서 관련 모듈을 가져옵니다.
# 관련 모듈 가져 오기 import pandas as pd import numpy as np import pandas_datareader.data as web import datetime import matplotlib.pyplot as plt import statistics as stat import random as rnd from matplotlib.ticker import StrMethodFormatter
지난 6 개월 동안의 과거 주가 데이터를 수집하고 싶습니다. 아래에서 데이터를 수집 할 관련 기간의 시작일과 종료일을 지정합니다.
# 주가 데이터 수집 기간에 대한 관련 시작 및 종료 날짜 지정 start_date = datetime.datetime(2020,4,1) end_date = datetime.datetime(2020,9,30)
다음으로 pandas_datareader를 통해 Yahoo Finance에서 수집 한 주가 데이터 프레임을 가져와 일일 수익으로 변환하는 도우미 함수를 정의합니다.
# 일일 수익 목록을 반환하는 함수 정의
def returns(df):
prices = df["Close"]
returns = [0 if i == 0 else (prices[i]-prices[i-1])/(prices[i-1]) for i in range(0,len(prices))]
return(returns)이제 주식 틱 목록을 가져와 특정 기간 동안의 일일 평균 수익률과 일일 수익률의 표준 편차를 계산하는 또 다른 도우미 함수를 정의합니다. 이 함수는 pandas_datareader를 사용하여 Yahoo에서 주가 데이터를 쿼리합니다.
# 표준 편차와 평균 일일 수익률로 데이터 프레임을 구성 할 수있는 함수 정의
def analyzeStocks(tickersArr,start_date,end_date):
# create empty data frame template
index = ["ticker","return","stdev"]
muArr = []
sigmaArr = []
# loop through all tickers
for i in range(0,len(tickersArr)):
# add ticker to table
tick = tickersArr[i]
# get stock price data
data = web.DataReader(tickersArr[i],"yahoo",start_date,end_date)
# calculate average daily return
muArr.append(stat.mean(returns(data)))
# calculate standard deviation
sigmaArr.append(stat.stdev(returns(data)))
# return a data frame
return(pd.DataFrame(np.array([tickersArr, muArr, sigmaArr]),index=index,columns=tickersArr))이 게시물에서는 아래의 진드기를 분석하고 싶습니다.
tickersArr = ["YATRY","KNX","BEST","YRCW","SNDR","ODFL","ARCB","WERN"]
이 게시물에서는 아래의 진드기를 분석하고 싶습니다.
base_df = analyzeStocks(tickersArr,start_date,end_date) base_df
위의 티커를 사용하여 주가 데이터를 가져오고 평균을 계산하기 위해 analyzeStocks를 실행합니다. 일일 수익 및 일일 수익의 표준 편차 :
| YATRY | KNX | BEST | YRCW | SNDR | ODFL | ARCB | WERN | |
|---|---|---|---|---|---|---|---|---|
| ticker | YATRY | KNX | BEST | YRCW | SNDR | ODFL | ARCB | WERN |
| return | 0.004653743523196298 | 0.0023175179239564793 | -0.0034124339485902665 | 0.011159199755783849 | 0.002462051717055063 | 0.003349259316178459 | 0.005861686829084918 | 0.0017903742321965712 |
| stdev | 0.02358463699374274 | 0.02114091659162514 | 0.031397841155750277 | 0.09455276239906354 | 0.019372571935633416 | 0.023305461738410294 | 0.037234069177970675 | 0.02237976138155402 |
matplotlib를 사용하여 단일 주식의 역사적 수익 대 변동성 성능에 대한 간단한 산점도를 만듭니다.
plt.figure(figsize=(15,8))
muArr = [float(i) for i in base_df.iloc[1,]]
sigmaArr = [float(i) for i in base_df.iloc[2,]]
sharpeArr = [muArr[i]/sigmaArr[i] for i in range(0,len(muArr))]
plt.scatter(sigmaArr,muArr,c=sharpeArr,cmap="plasma")
plt.title("Historical avg. returns vs. standard deviations [single stocks]",size=22)
plt.xlabel("Standard deviation",size=14)
plt.ylabel("Avg. daily return",size=14)Text(0, 0.5, 'Avg. daily return')

이제 포트폴리오 구축 기능을 정의합니다. 이 기능은 주 식당 무작위로 할당 된 가중치로 정의 된 수의 포트폴리오를 생성합니다. 이로 인한 일일 수익의 예상 수익과 표준 편차는 Pandas데이터 프레임의 형식으로 반환됩니다.
# 정의 된 수의 포트폴리오를 생성하기위한 기능 정의
def portfolioBuilder(n,tickersArr,start_date,end_date):
muArr = []
sigmaArr = []
dailyreturnsArr = []
weightedreturnsArr = []
portfoliodailyreturnsArr = []
# 일일 수익을 채우다
for i in range(0,len(tickersArr)):
data = web.DataReader(tickersArr[i],"yahoo",start_date,end_date)
dailyreturnsArr.append(returns(data))
# n 개의 다른 포트폴리오 생성
for i in range(0,n):
# 일일 포트폴리오 목록 재설정
portfoliodailyreturnsArr = []
# 포트폴리오 가중치 생성
weightsArr = [rnd.uniform(0,1) for i in range(0,len(tickersArr))]
nweightsArr = [i/sum(weightsArr) for i in weightsArr]
# 일일 수익에 무게를 두다
for j in range(0,len(dailyreturnsArr[0])):
temp = 0
for k in range(0,len(tickersArr)):
temp = temp + float(dailyreturnsArr[k][j])*float(nweightsArr[k])
portfoliodailyreturnsArr.append(temp)
# 평균 일일 가중치 포트폴리오 수익 계산 및 추가
muArr.append(stat.mean(portfoliodailyreturnsArr))
# 가중 포트폴리오의 일일 수익률 표준 편차 계산 및 추가
sigmaArr.append(stat.stdev(portfoliodailyreturnsArr))
# 생성 된 포트폴리오에 대한 기대 수익과 표준 편차를 반환합니다.
return([sigmaArr,muArr])포트폴리오 구축 기능을 시세에 적용하고 matplotlib.pyplot을 사용하여 500000 개의 무작위 포트폴리오를 사용하여 결과를 플로팅합니다.
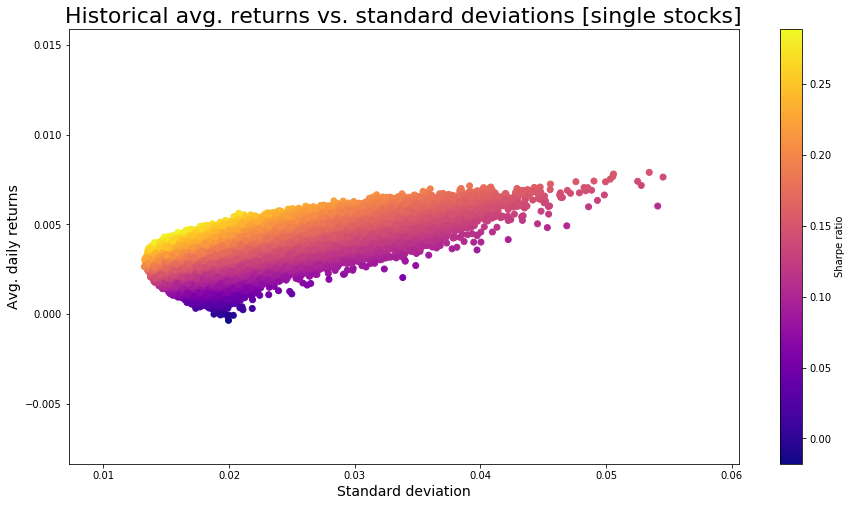
portfoliosArr = portfolioBuilder(500000,tickersArr,start_date,end_date)
plt.figure(figsize=(15,8))
muArr = [float(portfoliosArr[1][i]) for i in range(0,len(portfoliosArr[1]))]
sigmaArr = [float(portfoliosArr[0][i]) for i in range(0,len(portfoliosArr[0]))]
sharpeArr = [muArr[i]/sigmaArr[i] for i in range(0,len(muArr))]
plt.scatter(sigmaArr,muArr,c=sharpeArr,cmap="plasma")
plt.title("Historical avg. returns vs. standard deviations [single stocks]",size=22)
plt.colorbar(label="Sharpe ratio")
plt.xlabel("Standard deviation",size=14)
plt.ylabel("Avg. daily returns",size=14)Text(0, 0.5, 'Avg. daily returns')

이 차트를 사용하면 선택한 주식에 대해 현재 선택한 가중치가 현재 효율적인지 여부를 확인할 수 있습니다. 효율적인 포트폴리오는 산점도의 위쪽 선을 따라 배치됩니다.

최적화 및 시뮬레이션을 전문으로하는 산업 엔지니어 (R, Python, SQL, VBA)



Leave a Reply