“OECD”는 R의 패키지로, R 코드에서 직접 쿼리를 수행하기 위한 인터페이스를 제공합니다. 이 게시물에서는 “OECD” 패키지를 사용하여 유럽 운송 데이터를 분석합니다.
R에서 OECD 패키지를 읽는 것으로 시작합니다. 여기에는 “search_dataset” 함수가 포함되어 있으며 무엇을 할 수 있는지 읽고 싶습니다.
library(OECD)
?search_dataset“search_dataset”를 사용하면 첫 번째 매개변수로 함수에 제공된 검색 문자열을 기반으로 데이터 세트를 검색할 수 있습니다. “search_dataset”는 반환 출력으로 데이터 프레임을 반환합니다. 함수를 사용하여 흥미로운 전송 데이터가 포함된 데이터 세트를 찾도록 합시다.
head(search_dataset("transport"))## id
## 80 AIRTRANS_CO2
## 385 ETCR
## 452 MTC
## 482 CIF_FOB_ITIC
## 900 ITF_PASSENGER_TRANSPORT
## 934 ITF_GOODS_TRANSPORT
## title
## 80 Air Transport CO2 Emissions
## 385 Regulation in energy, transport and communications 2013
## 452 Maritime Transport Costs
## 482 International Transport and Insurance Costs of Merchandise Trade (ITIC)
## 900 Passenger transport
## 934 Freight transport당면한 게시물의 기사에 대해 “ITF_GOODS_TRANSPORT” 데이터 세트(화물 운송)를 사용하려고 합니다. “get_data_structure” 함수를 사용하여 쿼리합니다.
data_struct <- get_data_structure("ITF_GOODS_TRANSPORT")
typeof(data_struct)## [1] "list"목록의 내용을 살펴보겠습니다.
str(data_struct)## List of 9
## $ VAR_DESC :'data.frame': 9 obs. of 2 variables:
## ..$ id : chr [1:9] "COUNTRY" "VARIABLE" "YEAR" "OBS_VALUE" ...
## ..$ description: chr [1:9] "Country" "Variable" "Year" "Observation Value" ...
## $ COUNTRY :'data.frame': 58 obs. of 2 variables:
## ..$ id : chr [1:58] "ALB" "ARG" "ARM" "AUS" ...
## ..$ label: chr [1:58] "Albania" "Argentina" "Armenia" "Australia" ...
## $ VARIABLE :'data.frame': 14 obs. of 2 variables:
## ..$ id : chr [1:14] "T-GOODS-TOT-INLD" "T-GOODS-RL-TOT" "T-GOODS-RD-TOT" "T-GOODS-RD-REW" ...
## ..$ label: chr [1:14] "Total inland freight transport" "Rail freight transport" "Road freight transport" "Road freight transport for hire and reward" ...
## $ YEAR :'data.frame': 49 obs. of 2 variables:
## ..$ id : chr [1:49] "1970" "1971" "1972" "1973" ...
## ..$ label: chr [1:49] "1970" "1971" "1972" "1973" ...
## $ OBS_STATUS :'data.frame': 16 obs. of 2 variables:
## ..$ id : chr [1:16] "c" "B" "C" "D" ...
## ..$ label: chr [1:16] "Internal estimate" "Break" "Non-publishable and confidential value" "Difference in methodology" ...
## $ UNIT :'data.frame': 316 obs. of 2 variables:
## ..$ id : chr [1:316] "1" "GRWH" "AVGRW" "IDX" ...
## ..$ label: chr [1:316] "RATIOS" "Growth rate" "Average growth rate" "Index" ...
## $ POWERCODE :'data.frame': 32 obs. of 2 variables:
## ..$ id : chr [1:32] "0" "1" "2" "3" ...
## ..$ label: chr [1:32] "Units" "Tens" "Hundreds" "Thousands" ...
## $ REFERENCEPERIOD:'data.frame': 92 obs. of 2 variables:
## ..$ id : chr [1:92] "2013_100" "2012_100" "2011_100" "2010_100" ...
## ..$ label: chr [1:92] "2013=100" "2012=100" "2011=100" "2010=100" ...
## $ TIME_FORMAT :'data.frame': 5 obs. of 2 variables:
## ..$ id : chr [1:5] "P1Y" "P1M" "P3M" "P6M" ...
## ..$ label: chr [1:5] "Annual" "Monthly" "Quarterly" "Half-yearly" ...OECD에서 제공하는 데이터는 많은 차원을 가지고 있습니다. 이것이 “ITS_GOODS_TRANSPORT” 데이터 세트에 제공된 데이터의 차원과 구조를 이해하기 위해 get_data_structure를 사용한 이유입니다.
관련 필터를 적용하여 실제 데이터 세트를 쿼리하는 것으로 진행하겠습니다. 이를 위해 “OECD” R-패키지에서 제공하는 “get_dataset” 기능을 사용합니다.
data_df <- as.data.frame(get_dataset(dataset = "ITF_GOODS_TRANSPORT"))
head(data_df)## COUNTRY VARIABLE TIME_FORMAT UNIT POWERCODE obsTime obsValue
## 1 MKD T-CONT-SEA-TON P1Y TONNE 3 1970 NA
## 2 MKD T-CONT-SEA-TON P1Y TONNE 3 1971 NA
## 3 MKD T-CONT-SEA-TON P1Y TONNE 3 1972 NA
## 4 MKD T-CONT-SEA-TON P1Y TONNE 3 1973 NA
## 5 MKD T-CONT-SEA-TON P1Y TONNE 3 1974 NA
## 6 MKD T-CONT-SEA-TON P1Y TONNE 3 1975 NA
## OBS_STATUS
## 1 M
## 2 M
## 3 M
## 4 M
## 5 M
## 6 M일부 관련 데이터 하위 집합을 필터링할 수 있습니다.
backup_df <- data_df
library(dplyr)
colnames(data_df) <- c("country","variable","timeformat","unit","powercode","obsTime","obsValue","obsStatus")
data_df <- dplyr::filter(data_df,country=="DEU") # filter for Germany only
data_df <- dplyr::filter(data_df,timeformat=="P1Y") # filter for annual values only
data_df <- dplyr::filter(data_df,unit=="TONNEKM") # filter for figures in tonne kilometres only
# obsStatus indicates if the observation value is e.g. just an estimate or "ball-park-figure"
# you can see things like that by browsing through the entries of data_struct
data_df <- data_df[is.na(data_df$obsStatus),] # filtering out all estimates or "ball-park-figures"
# there are different variables in our dataset, as indicates by the "variable" column entries
unique(data_df$variable)## [1] "T-GOODS-RL-TOT" "T-GOODS-RD-REW" "T-GOODS-TOT-INLD" "T-GOODS-PP-TOT"
## [5] "T-GOODS-IW-TOT" "T-GOODS-RD-TOT" "T-SEA-CAB" "T-GOODS-RD-OWN"우리는 크게 부분 집합화했지만 나머지 데이터 프레임에는 여전히 다른 변수가 있습니다. 자세히 이해하려면 구조 개체, 즉 “data_struct” 개체로 돌아가야 합니다.
data_struct$VARIABLE## id label
## 1 T-GOODS-TOT-INLD Total inland freight transport
## 2 T-GOODS-RL-TOT Rail freight transport
## 3 T-GOODS-RD-TOT Road freight transport
## 4 T-GOODS-RD-REW Road freight transport for hire and reward
## 5 T-GOODS-RD-OWN Road freight transport on own account
## 6 T-GOODS-IW-TOT Inland waterways freight transport
## 7 T-GOODS-PP-TOT Pipelines transport
## 8 T-SEA-CAB Coastal shipping (national transport)
## 9 T-SEA Maritime transport
## 10 T-CONT-RL-TEU Rail containers transport (TEU)
## 11 T-CONT Containers transport
## 12 T-CONT-RL-TON Rail containers transport (weight)
## 13 T-CONT-SEA-TEU Maritime containers transport (TEU)
## 14 T-CONT-SEA-TON Maritime containers transport (weight)즉, 화물 운송에 대한 수치만 있는 것이 아니라 관련 하위 범주별 수치도 있습니다. 다른 게시물에서 추가 분석을 위해 이것을 사용할 것입니다. 이 게시물에서 우리는 전체 내륙 화물 운송을 계속 분석하고자 합니다.
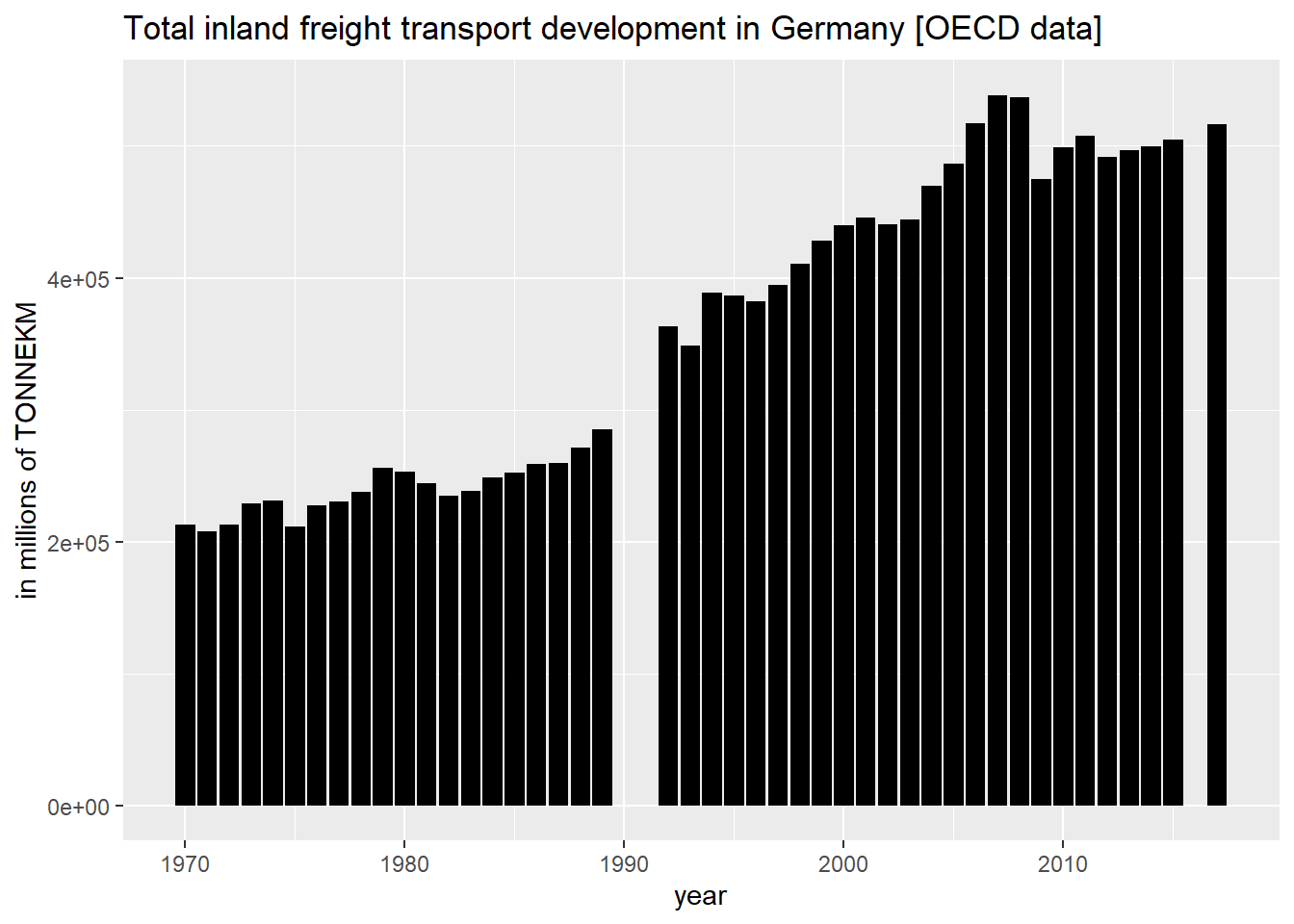
아래 차트는 독일의 총 내륙 화물 운송 톤 킬로미터[TONNEKM]의 시계열을 수백만(전원 코드 6)으로 시각화한 것입니다.
library(ggplot2)
ggplot(filter(data_df,variable=="T-GOODS-TOT-INLD")) +
geom_col(mapping = aes(x=as.numeric(obsTime),y=obsValue),fill="black") +
ggtitle("Total inland freight transport development in Germany [OECD data]") +
xlab("year") +
ylab("in millions of TONNEKM")
OECD R 패키지 외에도 R의 fredr 패키지 를 확인하고 싶을 수도 있습니다. Fredr 는 FRED 데이터베이스에 대한 액세스를 제공하는 공공 경제 데이터에 액세스하기 위한 또 다른 R 패키지입니다.

최적화 및 시뮬레이션을 전문으로하는 산업 엔지니어 (R, Python, SQL, VBA)



Leave a Reply