In this article I present an exemplary application of monte-carlo simulation for warehouse allocation. Monte-carlo simulation is a very popular technique when it comes to risk assessment. In previous posts I have introduced implementations of monte-carlo simulations in Python and R. I e.g. used monte-carlo simulation to assess the risk associated with price developments of commodities and stocks. I also demonstrated how to animate monte-carlo simulations in R using ggplot2 and gganimate.
In this article I will implement a monte-carlo simulation to assess the cost risk of a warehouse location being considered by my fictive board of directors. I will identify an estimated optimal warehouse location by applying the center of mass approach. I will then use monte-carlo simulation to assess cost risks associated with warehouse allocation at center of mass. That is, in this post, I will implement a workflow such as the one illustrated in the figure below.

Simple supply chain example for demonstrating monte-carlo simulation for warehouse allocation
For the purpose of demonstrating monte-carlo simulation for warehouse location risk assessment I will consider a simple supply chain network with direct supply from suplpiers, a single central distribution center (warehouse), and direct delivery to customers. The network model assumed is illustrated in below figure.

In this supply chain structure I consider, for this example, the shipped quantity of products (items) to be the relevant unit of measure as main variable explaining transportation costs. As I will also explain later, depending on the client and the data available, relevant units of measure when modelling the impact on variable transport costs might e.g. be weight or volume of shipments, amount of products shipped, or sales revenue and purchasing expenses.
In this example I will assume shipping volumes to be a relevant unit of measure. Such data will e.g. be available when relocating an existing warehouse or when using and extrapolating data from already existing distribution networks in another region with similar properties and product portfolios.
Setting up dataframe random customer/supplier locations and demand for monte-carlo simulation for warehouse allocation
In the code segment below I set up the dataframe containing supplier and customer locations as well as the expected shipping volume to or from every location. For a center of mass (center of gravity) analysis of this kind the direction of flow is not relevant, i.e. no distinguishment between shipping volumes from suppliers and to customers is made. This is based on a strong assumption. Namely that shipping prices per volume unit do not differ much on the sales side (towards customers) compared to the purchasing side (from suppliers). This is a strong assumption which in reality will often not be fulfilled.
The reason why this assumption is frequently not fully applicable in real-world problems is that there usually are structural differences in the incoming and outgoing material flow. For example, a distribution center might be receiving incoming shipments in larger lot sizes – such as e.g. full container loads. Outgoing shipments will in many cases however be smaller and e.g. take the form of parcel shipments. While parcel shipments and express deliveries often strongly correlate with the transportation distance, incoming sea freight containers or rail cargo might not depend on distances at all. In such cases one has to adjust the weights on one of the sides (either the sales or purchasing side). For example, sea freight might have to be excluded from a center of gravity analysis.
For this example let us however assume that incoming and outgoing shipment volumes have similar cost structures and both depend on the transportation distance.
# creating empty dataframe template
df = as.data.frame(matrix(nrow=1000,ncol=4))
# naming dataframe headers
colnames(df) = c("longitude",
"latitude",
"volume",
"type")
# the first 500 entries are going to be suppliers, the other 500 entries are representing customers
for(i in 1:1000){
if(i > 500){
df$type[i] = "customer"
}else{
df$type[i] = "supplier"
}
df$latitude[i] = rnorm(n=1,
mean = 50,
sd = 1)[1]
df$longitude[i] = rnorm(n=1,
mean=15,
sd=1)[1]
df$volume[i] = rnorm(n=1,
mean=100,
sd=25)[1]
}The artificially created dataframe should now be ready to use and fully populated. As you might have noticed I populated suppliers and customers with normally random distributed locations around longitude 50 and latitude 15. Shipping volume per supplier or customer follows a random distribution as well. Real-world data will off course look different, depending on the specific use case (dataset).
Choosing an optimal warehouse location based on center of mass approach, as a start point of the monte-carlo simulation for warehouse allocation
In a previous post I already demonstrated the center of mass approach as a simple optimization approach for locating a warehouse based on its proximity to customers (or suppliers, or both). In other words, this is a heuristical approach to optimal warehouse allocation. The centerof mass approach is commonly used in e.g. mechanical engineering. The picture below illustrates how the center of mass is derived from objects. These objects could be physical objects or abstract elements, such as e.g. customer demand. The mass, in that case, representing the respective cusomter`s demand.

As illustrated in the figure below the center of mass, or center of gravity, shifts when there is a shift in location-based weights (gravity).

The center of mass approach is based on some simplifying assumptions. These assumptions are as follows:
- Transport costs per shipment strongly correlate with transportation distance
- Correlation is assumed to be linear
- Transportation distance can be approximated with euclidean distance norms, i.e. straight lines
- Any structural differences in shipping classes, e.g. priority shipment vs. economy shipment, can be adjusted for by adjusting category-based relative weighting factors
The center of mass is also often referred to as center of gravity. The approach is also well explained with formulas. Here I show the formula for calculating the weighted average x-coordiante of the center of gravity (x being the longitude).

In the same way I can express the center of mass weighted average y-coordinate (latitude) with the same formula:

These formulas calculate, as stated, the weighted average x and y coordinates of the center of mass, respectively. The definition of weights can e.g. be based on the quantity of units shipped, the amount of sales revenue and purchasing expenses, or the amount or weight equivalents being or to be shipped. Depending on the data available at the client undergoing an warehouse allocation analysis of this kind one of these weight definitions will be the most appropriate to choose.
In below lines of code I derive the center of mass, representing the optimal warehouse location in this example. In other words: I implement the two formulas for calculating the average weighted x- and y-coordinates, weighted by the sales demand and supply amount of source supply quantity (suppliers) and sink demand quantity (customers). Only differences is that I refer to x as the longitude and y as the latitude.
# function derives center of mass, returning a vector with two entries
# return value no. 1: longitude coordinate of center of mass
# return value no. 2: latitude coordiante of center of mass
center_of_mass = function(df){
longitude = sum(df$volume*df$longitude)/sum(df$volume)
latitude = sum(df$volume*df$latitude)/sum(df$volume)
return(c(as.numeric(longitude),as.numeric(latitude)))
}Having implemented the formulas in the form of functions in R I now apply them to derive the center of mass for this example. The center of mass will be the assumed to represent the optimal warehouse location.
# apply center of mass calculating function
com = center_of_mass(df)I add the derived center of mass to the overall dataframe. This dataframe will later be used as input for ggplot2-based visualizations:
# add one more row with center of mass as separate entry
df[1001,] = c(com[1],
com[2],
200.0, # to make this point a little bit bigger on the ggplot2 based scatterplot
"CoM") # stands for "Center of Mass"
# make sure all numeric columns are really numeric
df$latitude = as.numeric(df$latitude)
df$longitude = as.numeric(df$longitude)
df$volume = as.numeric(df$volume)Visualizing optimal warehouse location based on center of mass approach
I can visualize the center of mass, i.e. the suggested optimal warehouse location, using a ggplot2 scatter plot.
# importing ggplot2 for scatter plot visualization
library(ggplot2)
# show the center of gravity using scatter plot
plot = ggplot() +
geom_point(data = df[-1001,], mapping = aes(x = longitude,
y = latitude,
color = type,
size = volume),alpha=0.05) +
geom_point(data=df[1001,],
mapping = aes(x=longitude,
y=latitude,
color=type,
size=volume)) +
scale_color_manual(values=c("black","red","blue")) +
xlab("Longitude") +
ylab("Latitude") +
ggtitle("Center of mass visualization with ggplot2 scatter plot") +
labs(color = "Type",
size = "Shipping volume")
# display plot
plot
I can visualize this on a map too, using ggmap. I have already introduced ggmap in another blog posts. Below is the point plot I created using ggmap in R (a ggplot2-based framework for map-based plotting).
# visualize scatter plot using ggmap
library(ggmap)
mapObj = get_stamenmap(
bbox = c(left = 5,
bottom = 45,
right = 25,
top = 55),
maptype = "toner-background",
zoom = 4)
mapatt = attributes(mapObj)
mapObj = matrix(adjustcolor(mapObj, alpha.f = 0.2), nrow = nrow(mapObj))
attributes(mapObj) = mapatt
mapObj = ggmap(mapObj)
mapObj = mapObj +
geom_point(data = df[-1001,], mapping = aes(x = longitude,
y = latitude,
color = type,
size = volume),alpha=0.05) +
geom_point(data=df[1001,],
mapping = aes(x=longitude,
y=latitude,
color=type,
size=volume)) +
scale_color_manual(values=c("black","red","blue")) +
xlab("Longitude") +
ylab("Latitude") +
ggtitle("Center of mass visualization with ggmap point plot") +
labs(color = "Type",
size = "Shipping volume")
mapObj
The differences in colors may irretate some analysts, as it can create some confusion with regards to volume density. Hence, one can also consider a plot with customers and suppliers being colored in the same color.
mapObj = get_stamenmap(
bbox = c(left = 5,
bottom = 45,
right = 25,
top = 55),
maptype = "toner-background",
zoom = 4)
mapatt = attributes(mapObj)
mapObj = matrix(adjustcolor(mapObj, alpha.f = 0.2), nrow = nrow(mapObj))
attributes(mapObj) = mapatt
mapObj = ggmap(mapObj)
mapObj = mapObj +
geom_point(data = df[-1001,], mapping = aes(x = longitude,
y = latitude,
color = type,
size = volume),alpha=0.03) +
geom_point(data=df[1001,],
mapping = aes(x=longitude,
y=latitude,
color=type,
size=volume)) +
scale_color_manual(values=c("black","red","red")) +
xlab("Longitude") +
ylab("Latitude") +
ggtitle("Center of mass visualization with ggmap point plot") +
labs(color = "Type",
size = "Shipping volume")
mapObj
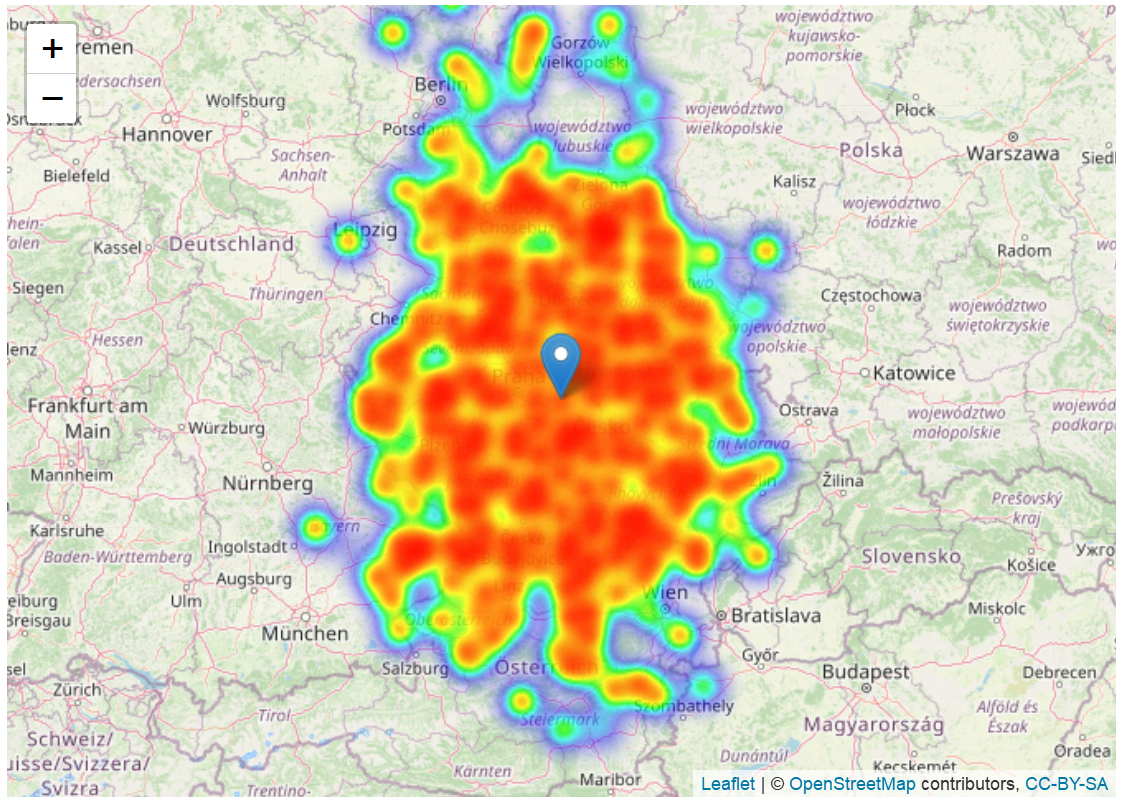
Another visualization approach would be to use the leaflet package in R for heatmapping shipping volume distribution, and to add a marker at center of gravity, i.e. center of mass. This is what I do in below lines of code. The leaflet package makes use of Leaflet.js.
# importing leaflet and leaflet.extras will enable me to make a heatmap
library(leaflet)
library(leaflet.extras)
library(magrittr)
# define center of map
lat_center = df$latitude[1001]
long_center = df$longitude[1001]
# creating a heat map for the burger search intensity
heatmap = df %>%
leaflet() %>%
addTiles() %>%
setView(long_center,lat_center,6.15) %>%
addHeatmap(lng=~longitude,lat=~latitude,intensity=~volume,max=100,radius=13,blur=20) %>%
addMarkers(lng=as.numeric(com[1]),lat=as.numeric(com[2]))
# display heatmap with center of gravity
heatmap
Calculating transport costs based on euclidean distance and shipping volume
I will proceed by implementing a function in R that calculates all expected transport costs. In this example I will focus on a highly simplified example in which I simply multiply euclidean distance with shipping volume. In real-world problems one could e.g. consider a zoned approach (e.g. FedEx bases its parcel shipping prices on zones).
The euclidean distance is the length of a straight line between two points in a 2D plane. Below follows the implementation of bespoken cost function.
# helper function for calculating euclidean distance metric
euclidean_distance = function(longitude,latitude,long_com,lat_com){
long_distances = (longitude-long_com[1])^2
lat_distances = (latitude-lat_com[1])^2
return((long_distances+lat_distances)*0.5)
}
# transport cost calculation function
transport_costs = function(df){
long_com = df$longitude[nrow(df)]
lat_com = df$latitude[nrow(df)]
euclideans = euclidean_distance(df$latitude[-nrow(df)],df$latitude[-nrow(df)],long_com,lat_com)
costs = euclideans*df$volume[-nrow(df)]
return(sum(costs))
}I will now apply the transport cost calculation function to see the total sum of transportation costs expected for the warehouse located at center of mass. I express costs in millions.
transport_costs(df)/1000000## [1] 60.8644Applying monte-carlo simulation to assess cost-risks associated to chosen warehouse location
Data, especially supply and demand data, is subject to volatility, seasonality and uncertainty. Monte-carlo simulation, one of the popular techniques used by SCM analysts, is an appropraite method for risk assessment. In this case there is risk involved in selecting a location for a new warehouse. How sensitive are transport costs if we choose this location? How much higher could transport costs be, compared to the transport costs calcualted above?
I can apply a monte-carlo simulation by applying repeating the experiment, applying normal distributions to the shipping volumes per customer and supplier. I will repeat the supply and demand scenario (i.e. the distribution of shipment volumes) 1,000 times. For each run I will calcualte the resulting transport costs and I will store the result of each run in a results dataframe.
# dataframe for storing monte-carlo simulation results
results = as.data.frame(matrix(nrow=10000,ncol=2))
colnames(results) = c("iteration","costs")
# execute 10,000 iterations of the monte-carlo simulation to assess cost uncertainty / cost
for(i in 1:10000){
df$volume[-1001] = rnorm(n=1000,
mean=100,
sd=25)
results$iteration[i] = i
results$costs[i] = transport_costs(df)/1000000
}
# plot results of monte-carlo simulation in the form of a histogram
ggplot() + geom_histogram(data = results,
mapping = aes(x=costs),
fill = "red",
bins = 25) +
ggtitle("Simulated transport cost sensitivity at center of gravity (center of mass)") +
xlab("Simulated transport costs") +
ylab("Absolute frequency")
This completes my example on how to apply monte-carlo simulation for warehouse allocation cost risk and sensitivity assessment. In other posts I have also demonstrated how one can e.g. animate monte-carlo simulation runs with gganimate in R, as well as I have demonstrated e.g. spatial demand distribution visualization in Python with packages such as Leaflet, or in R with packages such as deckgl.
References to related content
I recommend the articles below for anyone interested in diving deeper into monte-carlo simulation and warehouse allocation problems:
- Link: Prescriptive analytics in supply chain network design
- Link: Locating multiple warehouses at center of mass
- Link: Warehouse assignment problem
- Link: Single warehouse location problem
- Link: Capacitated facility location problem
- Link: New monte-carlo method for estimating network reliability

Data scientist focusing on simulation, optimization and modeling in R, SQL, VBA and Python



2 comments
Can I get the dataset for this problem?
Dear Aaykay. Thank you for you question.
As you will see in the coding examples embedded into the post the data is artificially created using distribution functions in R.