“OECD” is a package in R, providing an interface for performing a querry directly from R code. In this post I use the “OECD” package to analyze European transport data.
I begin by reading in the OECD package in R. It contains a function “search_dataset” and I want to read what it can do:
library(OECD)
?search_dataset## starting httpd help server ... done“search_dataset” allows us to search datasets, based on a search string provided to the function as first parameter. “search_dataset” will return a dataframe as return output. Lets use the the function to find a dataset that contains interesting transport data.
head(search_dataset("transport"))## id
## 80 AIRTRANS_CO2
## 385 ETCR
## 452 MTC
## 482 CIF_FOB_ITIC
## 900 ITF_PASSENGER_TRANSPORT
## 934 ITF_GOODS_TRANSPORT
## title
## 80 Air Transport CO2 Emissions
## 385 Regulation in energy, transport and communications 2013
## 452 Maritime Transport Costs
## 482 International Transport and Insurance Costs of Merchandise Trade (ITIC)
## 900 Passenger transport
## 934 Freight transportFor the article in the post at hand I want to use the “ITF_GOODS_TRANSPORT” dataset (freight transport). I querry it by using the “get_data_structure” function:
data_struct <- get_data_structure("ITF_GOODS_TRANSPORT")
typeof(data_struct) # what type os the data structure returned in by the function?## [1] "list"Let us see the content of the list:
str(data_struct)## List of 9
## $ VAR_DESC :'data.frame': 9 obs. of 2 variables:
## ..$ id : chr [1:9] "COUNTRY" "VARIABLE" "YEAR" "OBS_VALUE" ...
## ..$ description: chr [1:9] "Country" "Variable" "Year" "Observation Value" ...
## $ COUNTRY :'data.frame': 58 obs. of 2 variables:
## ..$ id : chr [1:58] "ALB" "ARG" "ARM" "AUS" ...
## ..$ label: chr [1:58] "Albania" "Argentina" "Armenia" "Australia" ...
## $ VARIABLE :'data.frame': 14 obs. of 2 variables:
## ..$ id : chr [1:14] "T-GOODS-TOT-INLD" "T-GOODS-RL-TOT" "T-GOODS-RD-TOT" "T-GOODS-RD-REW" ...
## ..$ label: chr [1:14] "Total inland freight transport" "Rail freight transport" "Road freight transport" "Road freight transport for hire and reward" ...
## $ YEAR :'data.frame': 49 obs. of 2 variables:
## ..$ id : chr [1:49] "1970" "1971" "1972" "1973" ...
## ..$ label: chr [1:49] "1970" "1971" "1972" "1973" ...
## $ OBS_STATUS :'data.frame': 16 obs. of 2 variables:
## ..$ id : chr [1:16] "c" "B" "C" "D" ...
## ..$ label: chr [1:16] "Internal estimate" "Break" "Non-publishable and confidential value" "Difference in methodology" ...
## $ UNIT :'data.frame': 316 obs. of 2 variables:
## ..$ id : chr [1:316] "1" "GRWH" "AVGRW" "IDX" ...
## ..$ label: chr [1:316] "RATIOS" "Growth rate" "Average growth rate" "Index" ...
## $ POWERCODE :'data.frame': 32 obs. of 2 variables:
## ..$ id : chr [1:32] "0" "1" "2" "3" ...
## ..$ label: chr [1:32] "Units" "Tens" "Hundreds" "Thousands" ...
## $ REFERENCEPERIOD:'data.frame': 92 obs. of 2 variables:
## ..$ id : chr [1:92] "2013_100" "2012_100" "2011_100" "2010_100" ...
## ..$ label: chr [1:92] "2013=100" "2012=100" "2011=100" "2010=100" ...
## $ TIME_FORMAT :'data.frame': 5 obs. of 2 variables:
## ..$ id : chr [1:5] "P1Y" "P1M" "P3M" "P6M" ...
## ..$ label: chr [1:5] "Annual" "Monthly" "Quarterly" "Half-yearly" ...The data provided by OECD has many dimensions. This is why I used get_data_structure – to understand the dimensions and structure of the data provided in the “ITS_GOODS_TRANSPORT” dataset.
Let us proceed to querrying the actual dataset, applying relevant filters. For this I use the “get_dataset” function provided by the “OECD” R-package:
data_df <- as.data.frame(get_dataset(dataset = "ITF_GOODS_TRANSPORT"))
# this may take a file since we are not using any filter setting in get_dataset
head(data_df)## COUNTRY VARIABLE TIME_FORMAT UNIT POWERCODE obsTime obsValue
## 1 MKD T-CONT-SEA-TON P1Y TONNE 3 1970 NA
## 2 MKD T-CONT-SEA-TON P1Y TONNE 3 1971 NA
## 3 MKD T-CONT-SEA-TON P1Y TONNE 3 1972 NA
## 4 MKD T-CONT-SEA-TON P1Y TONNE 3 1973 NA
## 5 MKD T-CONT-SEA-TON P1Y TONNE 3 1974 NA
## 6 MKD T-CONT-SEA-TON P1Y TONNE 3 1975 NA
## OBS_STATUS
## 1 M
## 2 M
## 3 M
## 4 M
## 5 M
## 6 MLets filter out some relevant subset of data:
backup_df <- data_df # in case I make a mistake I do not want to querry again
library(dplyr)##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unioncolnames(data_df) <- c("country","variable","timeformat","unit","powercode","obsTime","obsValue","obsStatus")
data_df <- dplyr::filter(data_df,country=="DEU") # filter for Germany only
data_df <- dplyr::filter(data_df,timeformat=="P1Y") # filter for annual values only
data_df <- dplyr::filter(data_df,unit=="TONNEKM") # filter for figures in tonne kilometres only
# obsStatus indicates if the observation value is e.g. just an estimate or "ball-park-figure"
# you can see things like that by browsing through the entries of data_struct
data_df <- data_df[is.na(data_df$obsStatus),] # filtering out all estimates or "ball-park-figures"
# there are different variables in our dataset, as indicates by the "variable" column entries
unique(data_df$variable)## [1] "T-GOODS-RL-TOT" "T-GOODS-RD-REW" "T-GOODS-TOT-INLD" "T-GOODS-PP-TOT"
## [5] "T-GOODS-IW-TOT" "T-GOODS-RD-TOT" "T-SEA-CAB" "T-GOODS-RD-OWN"We subsetted heavily, but the remaining dataframe still has different variables in it. If we want to understand those in detail we must go back to the structure object, i.e. the “data_struct” object:
data_struct$VARIABLE## id label
## 1 T-GOODS-TOT-INLD Total inland freight transport
## 2 T-GOODS-RL-TOT Rail freight transport
## 3 T-GOODS-RD-TOT Road freight transport
## 4 T-GOODS-RD-REW Road freight transport for hire and reward
## 5 T-GOODS-RD-OWN Road freight transport on own account
## 6 T-GOODS-IW-TOT Inland waterways freight transport
## 7 T-GOODS-PP-TOT Pipelines transport
## 8 T-SEA-CAB Coastal shipping (national transport)
## 9 T-SEA Maritime transport
## 10 T-CONT-RL-TEU Rail containers transport (TEU)
## 11 T-CONT Containers transport
## 12 T-CONT-RL-TON Rail containers transport (weight)
## 13 T-CONT-SEA-TEU Maritime containers transport (TEU)
## 14 T-CONT-SEA-TON Maritime containers transport (weight)This means that we do not just have figures for freight transport in sum, but we have figures by relevant sub-categories. We will use this for further analysis in other posts. In this post we want to continue analyzing total inland freight transport.
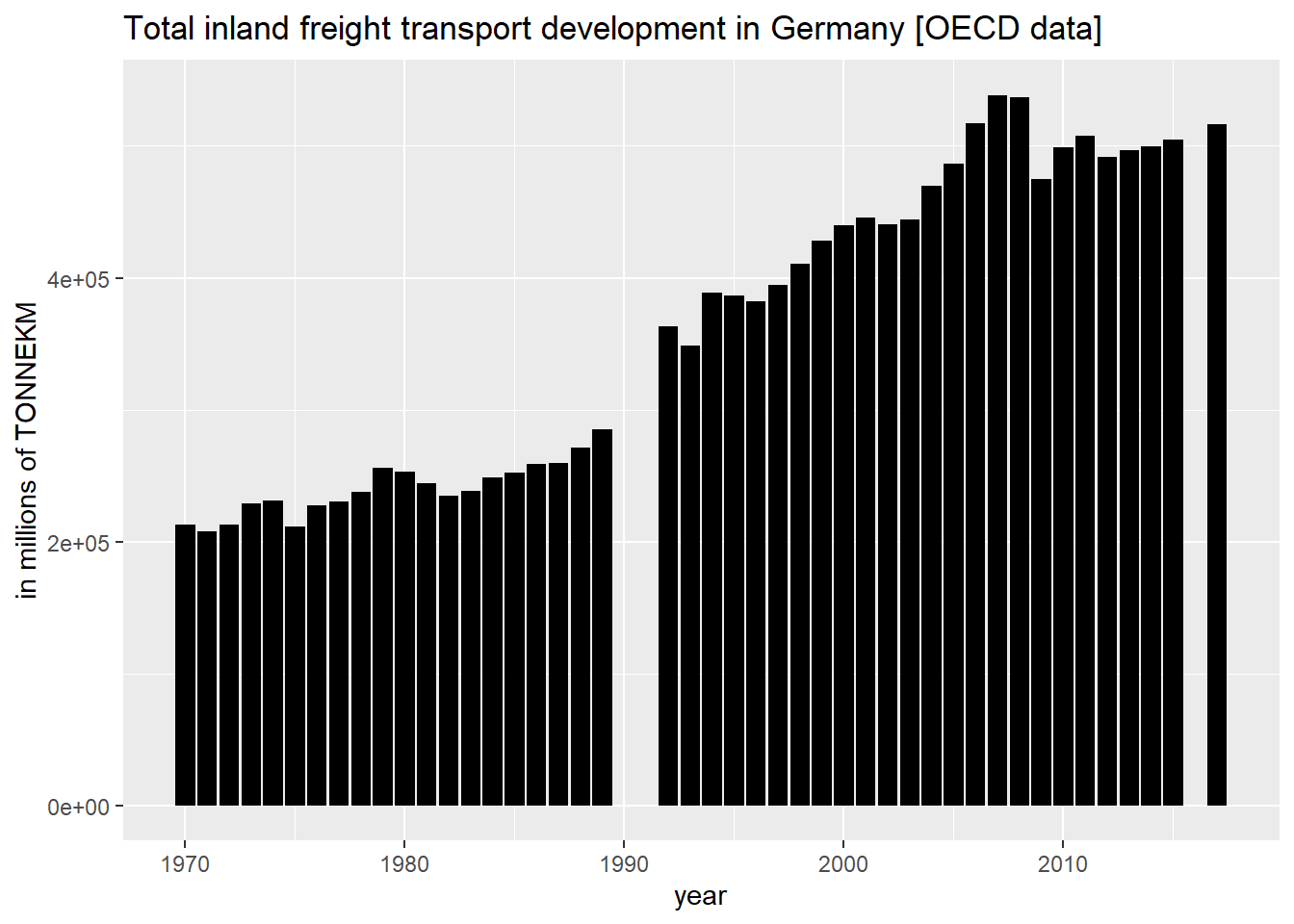
Below chart visualizes the timeseries of total inland freight transport tonne-kilometries [TONNEKM] in millions (powercode 6) for Germany:
library(ggplot2)
ggplot(filter(data_df,variable=="T-GOODS-TOT-INLD")) +
geom_col(mapping = aes(x=as.numeric(obsTime),y=obsValue),fill="black") +
ggtitle("Total inland freight transport development in Germany [OECD data]") +
xlab("year") +
ylab("in millions of TONNEKM")
Besides the OECD R-package you might also want to check the fredr package in R. Fredr is another R-package for accessing public economic data, providing access to the FRED database.

Data scientist focusing on simulation, optimization and modeling in R, SQL, VBA and Python



Leave a Reply