Fornecer um exemplo de codificação de como conduzir o agrupamento de clientes de proximidade espacial, aplicável, por exemplo, ao procurar vários centros de gravidade (ou seja, ao querer resolver um problema de localização de vários armazéns). A lógica e a abordagem são as mesmas de qualquer tipo de problema de agrupamento baseado em distância.
Aplicarei agrupamento k-means para agrupar clientes com base em sua distância espacial.
O algoritmo para agrupamento k-means é bem explicado, por exemplo, por este artigo: https://www.datanovia.com/en/lessons/k-means-clustering-in-r-algorith-and-practical-examples/
Primeiro, defino um dataframe contendo coordenadas aleatórias de latitude e longitude, representando clientes distribuídos aleatoriamente.
customer_df <- as.data.frame(matrix(nrow=1000,ncol=2))
colnames(customer_df) <- c("lat","long")
customer_df$lat <- runif(n=1000,min=-90,max=90)
customer_df$long <- runif(n=1000,min=-180,max=180)Aqui você vê o cabeçalho do dataframe:
head(customer_df)## lat long
## 1 67.260409 47.08063
## 2 55.400065 55.46616
## 3 -47.152065 -107.63843
## 4 -84.266658 -163.62681
## 5 -6.012361 103.34046
## 6 -10.717590 -59.64681O algoritmo padrão de agrupamento k-means seleciona k pontos iniciais aleatórios e os define como centros de agrupamento. O algoritmo então atribui pontos de dados para cada centro de cluster, com base na distância mínima.
Neste caso pretende-se posteriormente utilizar o algoritmo de agrupamento para resolver problemas de localização de instalações, considerando múltiplos armazéns a localizar. Portanto, parece mais apropriado selecionar centros de cluster que estejam razoavelmente distantes um do outro. Para isso, defino uma função que escolhe o número definido de centros iniciais com base na dimensão de longitude do conjunto de dados espaciais:
initial_centers <- function(customers,centers){
quantiles <- c()
for(i in 1:centers){
quantiles <- c(quantiles,i*as.integer(nrow(customers)/centers))
}
quantiles
}Agora podemos aplicar a função acima, em combinação com a função kmeans do pacote base do R. Neste exemplo, derivo quatro grupos de clientes baseados em proximidade.
cluster_obj <- kmeans(customer_df,centers=customer_df[initial_centers(customer_df,4),])
head(cluster_obj)## $cluster
## [1] 4 4 1 1 2 1 2 4 1 2 1 4 3 4 4 1 1 1 2 2 3 2 1 3 2 3 1 4 2 4 4 2 4 2
## [35] 1 4 4 2 2 1 3 2 2 1 3 2 4 3 2 1 1 2 2 3 4 1 4 2 2 3 2 1 2 1 2 2 2 3
## [69] 1 4 3 3 2 1 4 3 1 1 3 1 2 1 2 1 1 4 2 4 1 2 2 1 4 3 4 2 1 2 3 4 1 2
## [103] 3 3 4 4 4 1 4 3 1 4 1 2 2 1 3 2 3 2 4 3 4 3 2 1 1 2 2 2 4 4 4 1 2 2
## [137] 3 3 2 4 4 3 4 1 1 1 3 3 4 4 1 1 2 4 3 4 4 2 2 1 3 2 4 3 2 1 1 2 1 1
## [171] 2 1 1 1 4 3 3 1 2 3 2 4 2 2 2 4 3 2 1 4 1 2 4 2 3 2 2 2 2 2 1 2 2 1
## [205] 2 1 2 3 3 2 3 1 2 1 2 4 1 1 2 4 3 2 4 2 1 4 4 3 1 1 2 1 2 2 3 2 1 1
## [239] 3 1 3 1 2 1 2 1 1 4 1 1 2 2 1 2 1 4 1 4 2 2 2 2 4 4 1 3 3 1 1 4 3 4
## [273] 4 4 1 2 2 1 4 1 2 4 2 1 4 2 4 2 3 4 4 4 2 2 1 4 2 4 4 1 2 1 2 1 2 3
## [307] 1 1 1 1 2 3 3 3 1 4 4 1 2 1 4 1 4 3 2 4 3 2 1 2 2 4 2 4 2 2 2 4 2 1
## [341] 3 2 1 3 3 2 1 1 3 1 4 1 2 1 4 1 2 3 2 1 4 2 3 1 3 1 1 2 2 2 2 2 1 3
## [375] 2 2 1 2 4 4 1 3 1 2 3 4 2 4 4 1 1 2 4 4 4 2 3 4 1 3 2 3 4 1 3 3 1 4
## [409] 2 1 4 1 3 2 1 3 3 2 2 2 1 2 3 1 2 4 4 2 2 4 3 4 3 1 1 3 1 3 4 2 4 3
## [443] 3 3 4 1 1 2 1 3 2 1 1 2 1 4 2 2 1 1 2 1 2 4 2 4 3 2 1 1 1 4 2 3 1 4
## [477] 3 1 2 1 1 1 2 3 4 3 2 3 4 4 2 1 3 2 1 4 4 2 4 2 3 1 2 2 3 4 2 3 2 4
## [511] 3 4 2 4 2 1 3 2 1 4 2 4 3 1 1 4 2 2 2 1 4 2 1 3 1 4 1 4 2 3 4 3 1 2
## [545] 2 2 2 2 2 2 2 2 4 4 1 4 1 2 2 1 1 1 2 3 3 1 1 2 2 3 4 3 2 2 2 1 1 3
## [579] 4 2 1 4 1 3 3 1 1 1 2 3 1 2 3 1 4 4 1 1 3 1 4 1 2 3 3 2 4 4 2 4 2 2
## [613] 2 3 1 1 4 2 3 4 1 4 4 2 2 1 4 3 3 4 4 1 1 3 4 3 1 1 2 3 3 3 3 1 1 1
## [647] 4 1 2 1 2 4 2 4 2 2 3 4 4 2 4 1 2 1 1 4 2 1 1 2 1 4 4 1 3 3 1 3 4 4
## [681] 2 2 4 3 1 2 3 2 4 3 2 4 3 4 1 4 4 1 3 1 3 3 4 2 1 4 4 2 2 2 2 3 1 1
## [715] 1 2 1 4 1 3 1 2 2 4 3 3 2 2 1 3 2 2 1 1 3 4 3 3 1 1 2 1 1 4 2 4 1 4
## [749] 2 2 2 2 3 1 2 1 1 1 2 1 3 2 1 3 2 3 2 2 1 2 4 3 4 1 4 2 3 1 3 1 3 2
## [783] 3 1 1 1 1 1 4 2 2 1 2 1 4 1 4 3 4 1 2 1 1 4 2 1 4 4 3 4 2 3 1 3 2 3
## [817] 1 3 4 2 4 1 3 2 1 3 3 1 1 1 1 4 2 2 4 1 1 3 4 1 2 3 2 4 1 1 1 3 2 2
## [851] 1 3 3 2 3 1 2 2 3 2 1 4 1 1 1 3 2 1 3 1 2 3 2 4 2 2 2 2 1 3 4 3 1 4
## [885] 2 3 2 2 3 4 4 2 2 1 3 4 4 1 4 4 3 1 2 4 2 1 1 1 2 4 3 1 1 3 1 3 1 1
## [919] 4 3 1 2 1 3 2 4 2 1 4 2 1 3 1 2 1 3 3 1 2 1 1 1 1 1 1 3 4 4 2 1 2 2
## [953] 2 1 1 1 4 2 3 4 3 4 1 2 3 3 1 4 2 1 1 3 1 3 4 1 3 1 3 1 3 3 1 4 3 4
## [987] 1 3 2 4 4 2 3 4 3 2 4 2 3 2
##
## $centers
## lat long
## 1 0.6938018 -122.442238
## 2 -5.3567099 123.957813
## 3 -46.9979863 -2.714282
## 4 48.9979562 15.062099
##
## $totss
## [1] 13050174
##
## $withinss
## [1] 1108924.4 1028012.3 423675.5 523506.7
##
## $tot.withinss
## [1] 3084119
##
## $betweenss
## [1] 9966055Acima você vê o cabeçalho do objeto de resultado retornado pela função kmeans. Abaixo, combino os índices de cluster contidos no objeto kmeans com o dataframe do cliente, de forma que agora temos 3 colunas. Isso nos permitirá fazer ggplots etc.
result_df <- customer_df
result_df$group <- cluster_obj$cluster
head(result_df)## lat long group
## 1 67.260409 47.08063 4
## 2 55.400065 55.46616 4
## 3 -47.152065 -107.63843 1
## 4 -84.266658 -163.62681 1
## 5 -6.012361 103.34046 2
## 6 -10.717590 -59.64681 1Concluo este post visualizando os resultados em um ggplot (scatterplot usando o pacote ggplot2 R). Para colorir usei o pacote viridis no R:
library(ggplot2)
library(viridis)ggplot(result_df) + geom_point(mapping = aes(x=lat,y=long,color=group)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 
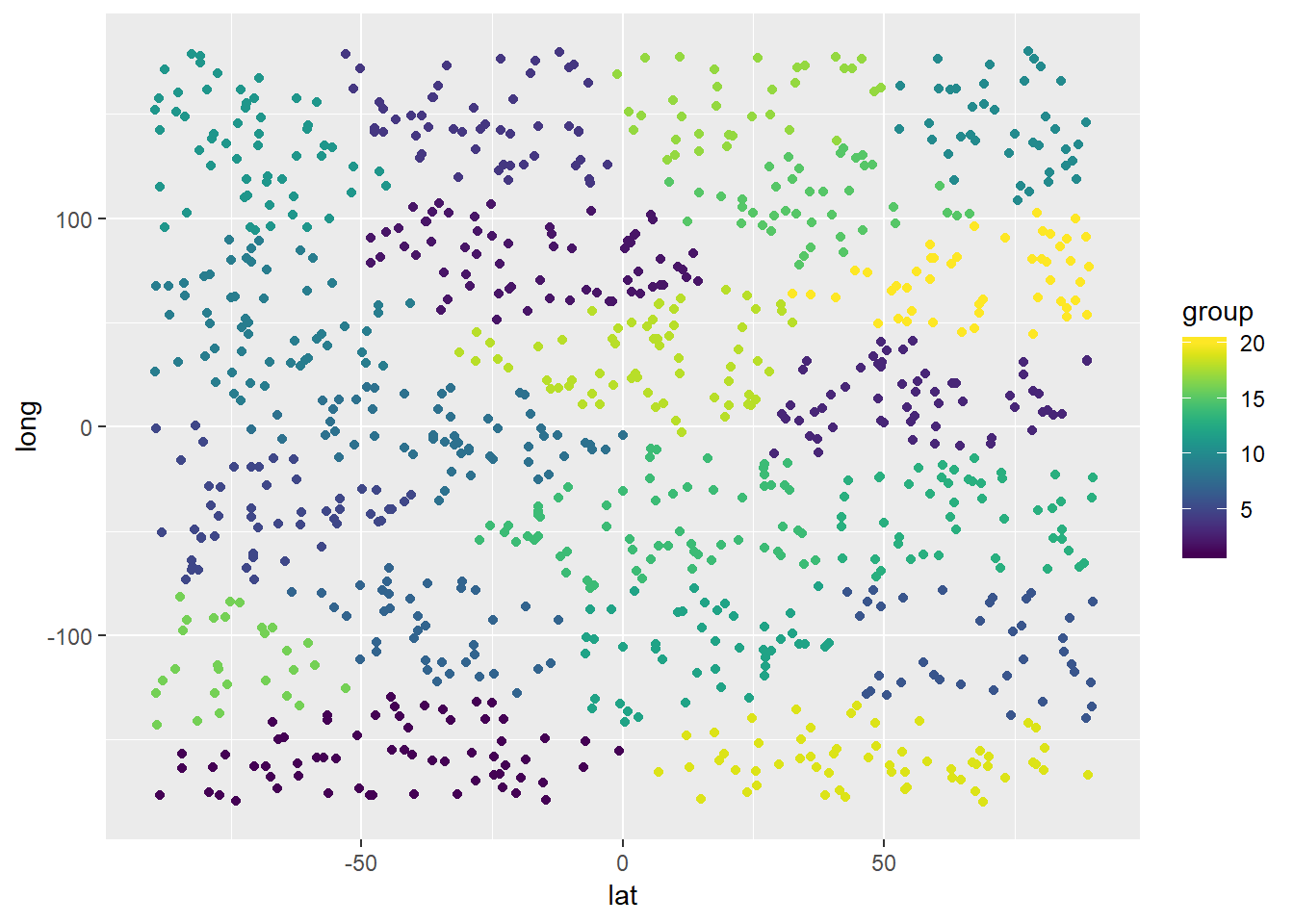
Vamos fazer outro teste com 20 armazéns:
cluster_obj <- kmeans(customer_df,centers=customer_df[initial_centers(customer_df,20),])
result_df$group <- cluster_obj$cluster
ggplot(result_df) + geom_point(mapping = aes(x=lat,y=long,color=group)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 
Se estiver interessado, confira meu post sobre o cálculo do centro de massa em R e como ele pode ser usado para resolver um problema de localização de armazém em R.

Cientista de dados com foco em simulação, otimização e modelagem em R, SQL, VBA e Python



Leave a Reply