“OECD” é um pacote em R, fornecendo uma interface para realizar uma consulta diretamente do código R. Neste post eu uso o pacote “OCDE” para analisar dados de transporte europeu.
Começo lendo o pacote OECD em R. Ele contém uma função “search_dataset” e quero ler o que ela pode fazer:
library(OECD)
?search_dataset“search_dataset” nos permite pesquisar conjuntos de dados, com base em uma string de pesquisa fornecida à função como primeiro parâmetro. “search_dataset” retornará um dataframe como saída de retorno. Vamos usar a função para encontrar um conjunto de dados que contenha dados de transporte interessantes.
head(search_dataset("transport"))## id
## 80 AIRTRANS_CO2
## 385 ETCR
## 452 MTC
## 482 CIF_FOB_ITIC
## 900 ITF_PASSENGER_TRANSPORT
## 934 ITF_GOODS_TRANSPORT
## title
## 80 Air Transport CO2 Emissions
## 385 Regulation in energy, transport and communications 2013
## 452 Maritime Transport Costs
## 482 International Transport and Insurance Costs of Merchandise Trade (ITIC)
## 900 Passenger transport
## 934 Freight transportPara o artigo do post em questão, quero usar o conjunto de dados “ITF_GOODS_TRANSPORT” (transporte de carga). Eu o consulto usando a função “get_data_structure”:
data_struct <- get_data_structure("ITF_GOODS_TRANSPORT")
typeof(data_struct)## [1] "list"Vejamos o conteúdo da lista:
str(data_struct)## List of 9
## $ VAR_DESC :'data.frame': 9 obs. of 2 variables:
## ..$ id : chr [1:9] "COUNTRY" "VARIABLE" "YEAR" "OBS_VALUE" ...
## ..$ description: chr [1:9] "Country" "Variable" "Year" "Observation Value" ...
## $ COUNTRY :'data.frame': 58 obs. of 2 variables:
## ..$ id : chr [1:58] "ALB" "ARG" "ARM" "AUS" ...
## ..$ label: chr [1:58] "Albania" "Argentina" "Armenia" "Australia" ...
## $ VARIABLE :'data.frame': 14 obs. of 2 variables:
## ..$ id : chr [1:14] "T-GOODS-TOT-INLD" "T-GOODS-RL-TOT" "T-GOODS-RD-TOT" "T-GOODS-RD-REW" ...
## ..$ label: chr [1:14] "Total inland freight transport" "Rail freight transport" "Road freight transport" "Road freight transport for hire and reward" ...
## $ YEAR :'data.frame': 49 obs. of 2 variables:
## ..$ id : chr [1:49] "1970" "1971" "1972" "1973" ...
## ..$ label: chr [1:49] "1970" "1971" "1972" "1973" ...
## $ OBS_STATUS :'data.frame': 16 obs. of 2 variables:
## ..$ id : chr [1:16] "c" "B" "C" "D" ...
## ..$ label: chr [1:16] "Internal estimate" "Break" "Non-publishable and confidential value" "Difference in methodology" ...
## $ UNIT :'data.frame': 316 obs. of 2 variables:
## ..$ id : chr [1:316] "1" "GRWH" "AVGRW" "IDX" ...
## ..$ label: chr [1:316] "RATIOS" "Growth rate" "Average growth rate" "Index" ...
## $ POWERCODE :'data.frame': 32 obs. of 2 variables:
## ..$ id : chr [1:32] "0" "1" "2" "3" ...
## ..$ label: chr [1:32] "Units" "Tens" "Hundreds" "Thousands" ...
## $ REFERENCEPERIOD:'data.frame': 92 obs. of 2 variables:
## ..$ id : chr [1:92] "2013_100" "2012_100" "2011_100" "2010_100" ...
## ..$ label: chr [1:92] "2013=100" "2012=100" "2011=100" "2010=100" ...
## $ TIME_FORMAT :'data.frame': 5 obs. of 2 variables:
## ..$ id : chr [1:5] "P1Y" "P1M" "P3M" "P6M" ...
## ..$ label: chr [1:5] "Annual" "Monthly" "Quarterly" "Half-yearly" ...Os dados fornecidos pela OCDE têm muitas dimensões. É por isso que usei get_data_structure – para entender as dimensões e a estrutura dos dados fornecidos no conjunto de dados “ITS_GOODS_TRANSPORT”.
Vamos continuar consultando o conjunto de dados real, aplicando os filtros relevantes. Para isso, uso a função “get_dataset” fornecida pelo pacote R “OECD”:
data_df <- as.data.frame(get_dataset(dataset = "ITF_GOODS_TRANSPORT"))
head(data_df)## COUNTRY VARIABLE TIME_FORMAT UNIT POWERCODE obsTime obsValue
## 1 MKD T-CONT-SEA-TON P1Y TONNE 3 1970 NA
## 2 MKD T-CONT-SEA-TON P1Y TONNE 3 1971 NA
## 3 MKD T-CONT-SEA-TON P1Y TONNE 3 1972 NA
## 4 MKD T-CONT-SEA-TON P1Y TONNE 3 1973 NA
## 5 MKD T-CONT-SEA-TON P1Y TONNE 3 1974 NA
## 6 MKD T-CONT-SEA-TON P1Y TONNE 3 1975 NA
## OBS_STATUS
## 1 M
## 2 M
## 3 M
## 4 M
## 5 M
## 6 MVamos filtrar alguns subconjuntos relevantes de dados:
backup_df <- data_df
library(dplyr)colnames(data_df) <- c("country","variable","timeformat","unit","powercode","obsTime","obsValue","obsStatus")
data_df <- dplyr::filter(data_df,country=="DEU")
data_df <- dplyr::filter(data_df,timeformat=="P1Y")
data_df <- dplyr::filter(data_df,unit=="TONNEKM")
data_df <- data_df[is.na(data_df$obsStatus),]
unique(data_df$variable)## [1] "T-GOODS-RL-TOT" "T-GOODS-RD-REW" "T-GOODS-TOT-INLD" "T-GOODS-PP-TOT"
## [5] "T-GOODS-IW-TOT" "T-GOODS-RD-TOT" "T-SEA-CAB" "T-GOODS-RD-OWN"Nós subdividimos pesadamente, mas o quadro de dados restante ainda possui variáveis diferentes. Se quisermos entendê-los em detalhes, devemos voltar ao objeto de estrutura, ou seja, o objeto “data_struct”:
data_struct$VARIABLE## id label
## 1 T-GOODS-TOT-INLD Total inland freight transport
## 2 T-GOODS-RL-TOT Rail freight transport
## 3 T-GOODS-RD-TOT Road freight transport
## 4 T-GOODS-RD-REW Road freight transport for hire and reward
## 5 T-GOODS-RD-OWN Road freight transport on own account
## 6 T-GOODS-IW-TOT Inland waterways freight transport
## 7 T-GOODS-PP-TOT Pipelines transport
## 8 T-SEA-CAB Coastal shipping (national transport)
## 9 T-SEA Maritime transport
## 10 T-CONT-RL-TEU Rail containers transport (TEU)
## 11 T-CONT Containers transport
## 12 T-CONT-RL-TON Rail containers transport (weight)
## 13 T-CONT-SEA-TEU Maritime containers transport (TEU)
## 14 T-CONT-SEA-TON Maritime containers transport (weight)Isso significa que não temos apenas números para o transporte de mercadorias em soma, mas temos números por subcategorias relevantes. Usaremos isso para uma análise mais aprofundada em outros posts. Neste post, queremos continuar analisando o transporte terrestre total de mercadorias.
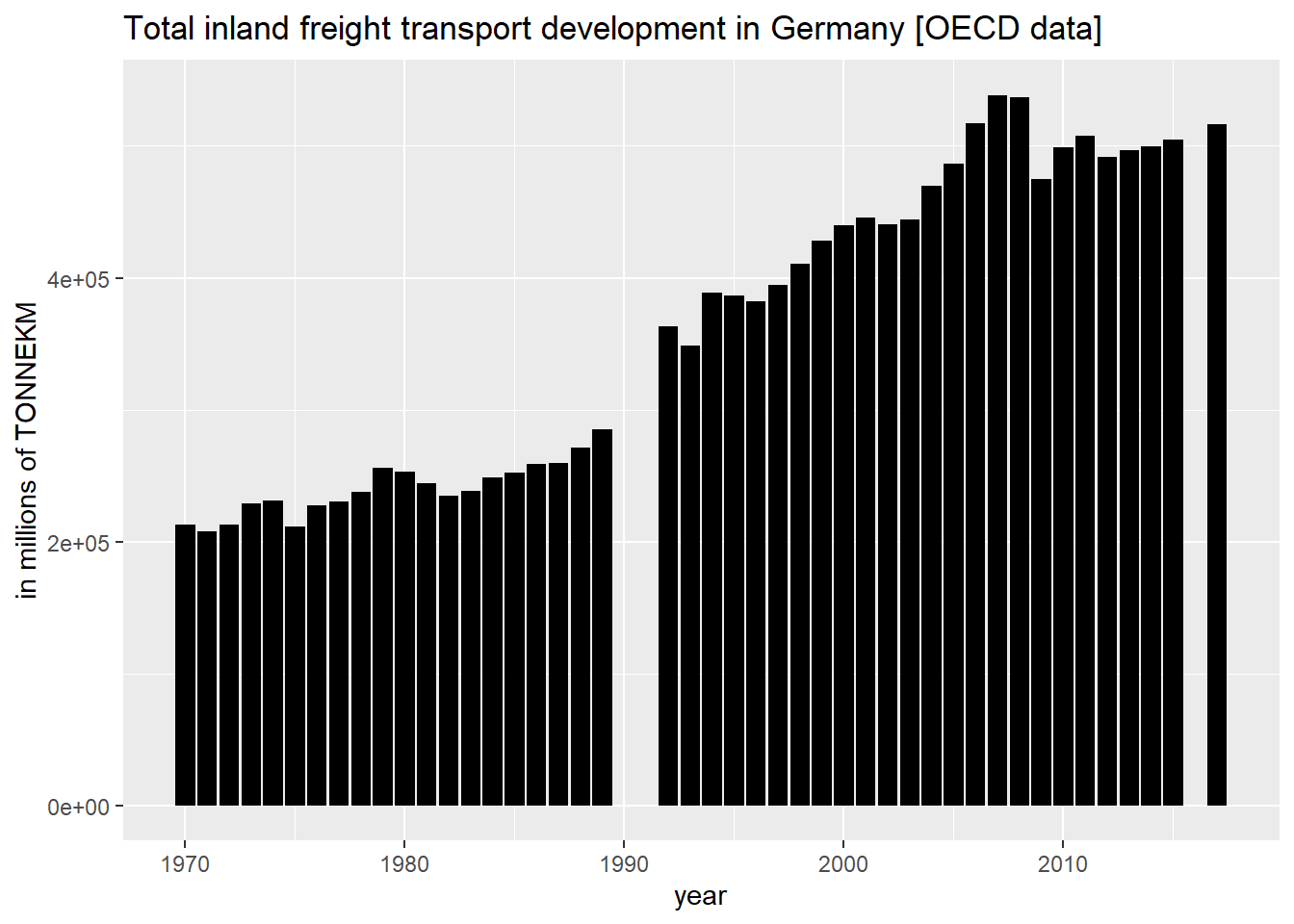
O gráfico abaixo visualiza a série temporal do total de toneladas-quilômetros de transporte terrestre de carga [TONNEKM] em milhões (powercode 6) para a Alemanha:
library(ggplot2)
ggplot(filter(data_df,variable=="T-GOODS-TOT-INLD")) +
geom_col(mapping = aes(x=as.numeric(obsTime),y=obsValue),fill="black") +
ggtitle("Total inland freight transport development in Germany [OECD data]") +
xlab("year") +
ylab("in millions of TONNEKM")
Além do pacote R da OCDE, você também pode querer verificar o pacote fredr em R. Fredr é outro pacote R para acessar dados econômicos públicos, fornecendo acesso ao banco de dados FRED.

Cientista de dados com foco em simulação, otimização e modelagem em R, SQL, VBA e Python



Leave a Reply