Em um post anterior, expliquei a previsão baseada em CAGR. A previsão baseada em CAGR é um método de previsão muito simples que é frequentemente aplicado na indústria, por exemplo, para previsão de vendas e produção.
Modelos de previsão simples têm benefícios. Eles são fáceis de entender e fáceis de implementar. Além disso, eles contêm poucos parâmetros e, portanto, são muito precisos em suas principais suposições. Desta forma, pode-se dizer que métodos simples de previsão são, em muitos casos, os melhores métodos de previsão. Em outras palavras: se você tentar prever o futuro, pode muito bem fazê-lo com um modelo de previsão que você entenda completamente e que possa explicar a qualquer pessoa a qualquer momento.
Nesta postagem, gostaria de apresentar a previsão de séries temporais com base em um cálculo simples de média móvel. As médias móveis, também conhecidas como médias móveis ou meios móveis, são usadas para analisar e pré-processar dados históricos de séries temporais. No entanto, eles podem ser usados para criar um algoritmo de previsão simples.
Eu diferencio a previsão de média móvel simples em duas categorias:
(a) previsão a partir de dados históricos, calculando uma média móvel
(b) o mesmo que (a), mas com um parâmetro de crescimento intrínseco adicional
A categoria (b) é, portanto, uma combinação de previsão baseada em CAGR e previsão de média móvel.
Como a previsão baseada em CAGR, a previsão de média móvel simples pode ser usada apenas para horizontes de tempo limite.
Eu implemento essa abordagem de previsão no exemplo de codificação abaixo, usando uma função que calcula uma média móvel de comprimento definido. Eu implemento essa função no R e a aplico para prever valores futuros. Eu chamo a função de “sma_forecast”. É implementado no código R abaixo:
sma_forecast = function(past,length){
future = rep(0,times = length)
prediction = c(past,future)
for(i in (length(past)+1):length(prediction)){
prediction[i] = mean(prediction[(i-length(past)):(i-1)])
}
return(prediction)
}A próxima etapa neste fluxo de trabalho é ler os dados históricos. Neste caso, li dados sobre a produção anual da indústria automotiva por país, medida em número de unidades produzidas em um determinado ano em um determinado país. A última etapa é calcular a previsão, usando o sma_forecast. Tudo isso é feito no exemplo de codificação abaixo, usando R:
library(readxl)
data_df = as.data.frame(read_xls("oica.xls"))
head(data_df)## year country total
## 1 2018 Argentina 466649
## 2 2018 Austria 164900
## 3 2018 Belgium 308493
## 4 2018 Brazil 2879809
## 5 2018 Canada 2020840
## 6 2018 China 27809196tail(data_df)## year country total
## 835 1999 Turkey 297862
## 836 1999 Ukraine 1918
## 837 1999 UK 1973519
## 838 1999 USA 13024978
## 839 1999 Uzbekistan 44433
## 840 1999 Others 11965library(dplyr)
data_df = filter(data_df,country=="USA")
library(ggplot2)
ggplot(data_df) +
geom_path(mapping = aes(x = year, y = total/1000000),
size = 2,
color = "red") +
labs(title = "US automotive industry production output",
subtitle = "historical OICA data, for 1999 - 2018") +
xlab("year") +
ylab("output [millions of units]") +
ylim(0,15)
library(dplyr)
data_df = data_df %>% arrange(desc(-year))
predictionVals = sma_forecast(past=data_df$total,length = 10)
plot_df = as.data.frame(matrix(nrow=length(predictionVals),ncol= 4))
colnames(plot_df) = c("year","country","total","category")
plot_df$total = predictionVals
plot_df$category[1:nrow(data_df)] = "history"
plot_df$category[(nrow(data_df)+1):length(predictionVals)] = "prediction"
plot_df$year = data_df$year[1]:(data_df$year[1]+length(predictionVals)-1)
plot_df$country = data_df$country[1]
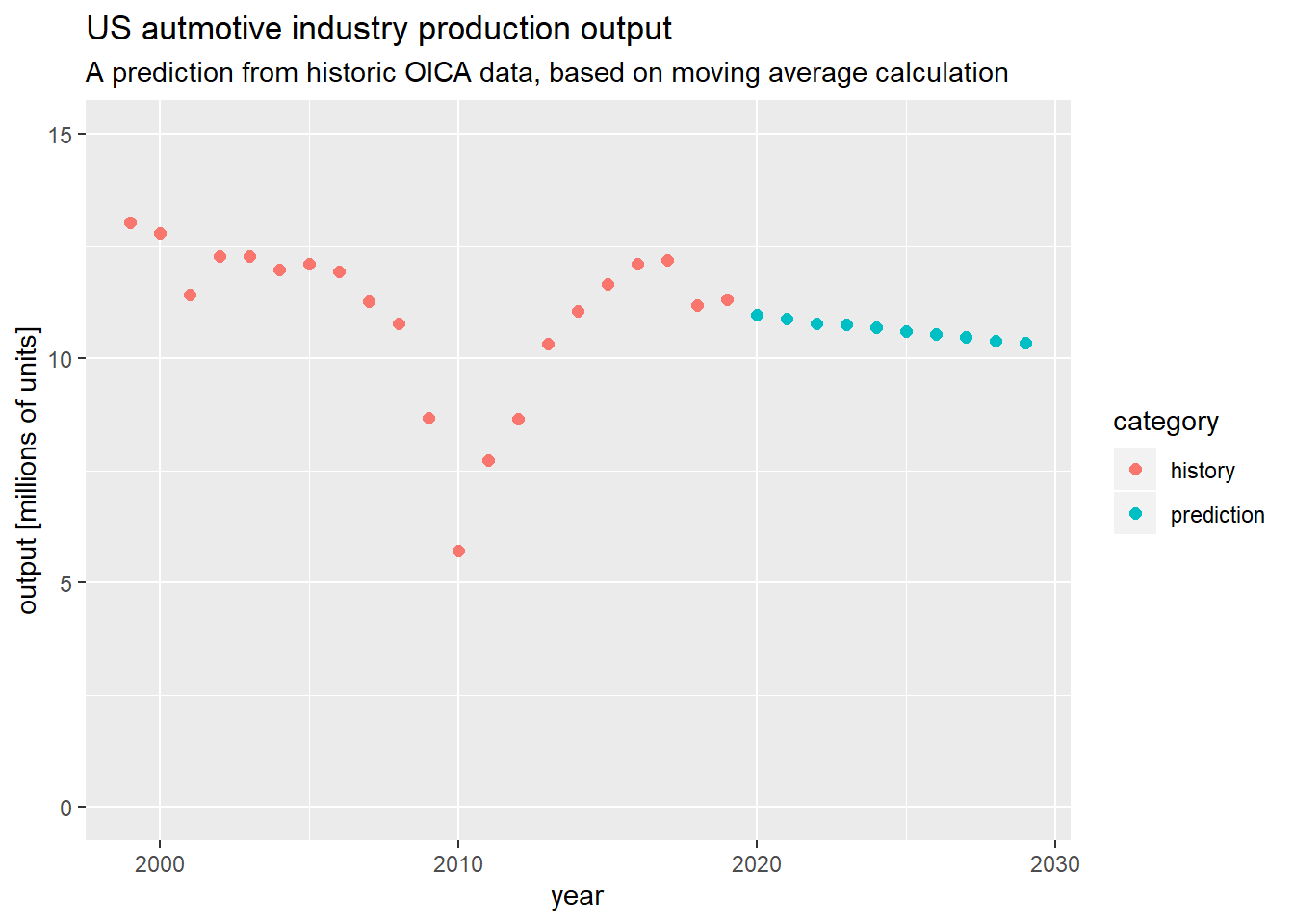
ggplot(plot_df) +
geom_point(mapping = aes(x = year,
y = total/1000000,
color = category),
size = 2) +
labs(title = "US autmotive industry production output",
subtitle = "A prediction from historic OICA data, based on moving average calculation") +
xlab("year") +
ylab("output [millions of units]") +
ylim(0,15)
Termino meu exemplo neste ponto.
Coisas que eu poderia ter adicionado:
(a) Divisão em conjunto de treinamento e teste para avaliar o método
(b) Avalie o método para vários países, intervalos de tempo e comprimentos de previsões
(c) Testar a previsão em dados diferentes dos dados de saída de produção
(d) …
Se você achou esta postagem interessante, considere verificar minhas outras postagens, por exemplo, previsão baseada em CAGR, obtenção e análise de dados OICA, análise de séries temporais, programação linear, fontes públicas para dados de vendas da indústria automotiva, etc.

Cientista de dados com foco em simulação, otimização e modelagem em R, SQL, VBA e Python



Leave a Reply