提供一个如何进行空间近似客户聚类的编码示例,适用于例如搜索多个重心时(即想解决多个仓库位置问题时)。其逻辑和方法与任何一种基于距离的聚类问题都是一样的。
我将k应用k-means聚类来根据客户的空间距离进行分组。
k-means聚类的算法有很好的解释,如本文:https://www.datanovia.com/en/lessons/k-means-clustering-in-r-algorith-and-practical-examples/。
首先我定义了一个包含随机经纬度坐标的数据框架,代表随机分布的客户。
customer_df <- as.data.frame(matrix(nrow=1000,ncol=2))
colnames(customer_df) <- c("lat","long")
customer_df$lat <- runif(n=1000,min=-90,max=90)
customer_df$long <- runif(n=1000,min=-180,max=180)这里你可以看到数据框架的头。
head(customer_df)## lat long
## 1 67.260409 47.08063
## 2 55.400065 55.46616
## 3 -47.152065 -107.63843
## 4 -84.266658 -163.62681
## 5 -6.012361 103.34046
## 6 -10.717590 -59.64681标准的k-means聚类算法选择k个随机初始点,并将这些点定义为聚类中心。然后算法根据最小距离,将数据点分配给每个聚类中心。
在这种情况下,我们以后要使用聚类算法来解决设施定位问题,考虑多个仓库的定位。因此,我认为选择彼此距离合理的聚类中心比较合适。为此我定义了一个函数,根据空间数据集的经度维度来选择定义的起始中心数量。
initial_centers <- function(customers,centers){
quantiles <- c()
for(i in 1:centers){
quantiles <- c(quantiles,i*as.integer(nrow(customers)/centers))
}
quantiles
}现在我们可以结合R基础包中的kmeans函数,应用上面的函数。在这个例子中,我推导出四个基于接近性的客户群。
cluster_obj <- kmeans(customer_df,centers=customer_df[initial_centers(customer_df,4),])
head(cluster_obj)## $cluster
## [1] 4 4 1 1 2 1 2 4 1 2 1 4 3 4 4 1 1 1 2 2 3 2 1 3 2 3 1 4 2 4 4 2 4 2
## [35] 1 4 4 2 2 1 3 2 2 1 3 2 4 3 2 1 1 2 2 3 4 1 4 2 2 3 2 1 2 1 2 2 2 3
## [69] 1 4 3 3 2 1 4 3 1 1 3 1 2 1 2 1 1 4 2 4 1 2 2 1 4 3 4 2 1 2 3 4 1 2
## [103] 3 3 4 4 4 1 4 3 1 4 1 2 2 1 3 2 3 2 4 3 4 3 2 1 1 2 2 2 4 4 4 1 2 2
## [137] 3 3 2 4 4 3 4 1 1 1 3 3 4 4 1 1 2 4 3 4 4 2 2 1 3 2 4 3 2 1 1 2 1 1
## [171] 2 1 1 1 4 3 3 1 2 3 2 4 2 2 2 4 3 2 1 4 1 2 4 2 3 2 2 2 2 2 1 2 2 1
## [205] 2 1 2 3 3 2 3 1 2 1 2 4 1 1 2 4 3 2 4 2 1 4 4 3 1 1 2 1 2 2 3 2 1 1
## [239] 3 1 3 1 2 1 2 1 1 4 1 1 2 2 1 2 1 4 1 4 2 2 2 2 4 4 1 3 3 1 1 4 3 4
## [273] 4 4 1 2 2 1 4 1 2 4 2 1 4 2 4 2 3 4 4 4 2 2 1 4 2 4 4 1 2 1 2 1 2 3
## [307] 1 1 1 1 2 3 3 3 1 4 4 1 2 1 4 1 4 3 2 4 3 2 1 2 2 4 2 4 2 2 2 4 2 1
## [341] 3 2 1 3 3 2 1 1 3 1 4 1 2 1 4 1 2 3 2 1 4 2 3 1 3 1 1 2 2 2 2 2 1 3
## [375] 2 2 1 2 4 4 1 3 1 2 3 4 2 4 4 1 1 2 4 4 4 2 3 4 1 3 2 3 4 1 3 3 1 4
## [409] 2 1 4 1 3 2 1 3 3 2 2 2 1 2 3 1 2 4 4 2 2 4 3 4 3 1 1 3 1 3 4 2 4 3
## [443] 3 3 4 1 1 2 1 3 2 1 1 2 1 4 2 2 1 1 2 1 2 4 2 4 3 2 1 1 1 4 2 3 1 4
## [477] 3 1 2 1 1 1 2 3 4 3 2 3 4 4 2 1 3 2 1 4 4 2 4 2 3 1 2 2 3 4 2 3 2 4
## [511] 3 4 2 4 2 1 3 2 1 4 2 4 3 1 1 4 2 2 2 1 4 2 1 3 1 4 1 4 2 3 4 3 1 2
## [545] 2 2 2 2 2 2 2 2 4 4 1 4 1 2 2 1 1 1 2 3 3 1 1 2 2 3 4 3 2 2 2 1 1 3
## [579] 4 2 1 4 1 3 3 1 1 1 2 3 1 2 3 1 4 4 1 1 3 1 4 1 2 3 3 2 4 4 2 4 2 2
## [613] 2 3 1 1 4 2 3 4 1 4 4 2 2 1 4 3 3 4 4 1 1 3 4 3 1 1 2 3 3 3 3 1 1 1
## [647] 4 1 2 1 2 4 2 4 2 2 3 4 4 2 4 1 2 1 1 4 2 1 1 2 1 4 4 1 3 3 1 3 4 4
## [681] 2 2 4 3 1 2 3 2 4 3 2 4 3 4 1 4 4 1 3 1 3 3 4 2 1 4 4 2 2 2 2 3 1 1
## [715] 1 2 1 4 1 3 1 2 2 4 3 3 2 2 1 3 2 2 1 1 3 4 3 3 1 1 2 1 1 4 2 4 1 4
## [749] 2 2 2 2 3 1 2 1 1 1 2 1 3 2 1 3 2 3 2 2 1 2 4 3 4 1 4 2 3 1 3 1 3 2
## [783] 3 1 1 1 1 1 4 2 2 1 2 1 4 1 4 3 4 1 2 1 1 4 2 1 4 4 3 4 2 3 1 3 2 3
## [817] 1 3 4 2 4 1 3 2 1 3 3 1 1 1 1 4 2 2 4 1 1 3 4 1 2 3 2 4 1 1 1 3 2 2
## [851] 1 3 3 2 3 1 2 2 3 2 1 4 1 1 1 3 2 1 3 1 2 3 2 4 2 2 2 2 1 3 4 3 1 4
## [885] 2 3 2 2 3 4 4 2 2 1 3 4 4 1 4 4 3 1 2 4 2 1 1 1 2 4 3 1 1 3 1 3 1 1
## [919] 4 3 1 2 1 3 2 4 2 1 4 2 1 3 1 2 1 3 3 1 2 1 1 1 1 1 1 3 4 4 2 1 2 2
## [953] 2 1 1 1 4 2 3 4 3 4 1 2 3 3 1 4 2 1 1 3 1 3 4 1 3 1 3 1 3 3 1 4 3 4
## [987] 1 3 2 4 4 2 3 4 3 2 4 2 3 2
##
## $centers
## lat long
## 1 0.6938018 -122.442238
## 2 -5.3567099 123.957813
## 3 -46.9979863 -2.714282
## 4 48.9979562 15.062099
##
## $totss
## [1] 13050174
##
## $withinss
## [1] 1108924.4 1028012.3 423675.5 523506.7
##
## $tot.withinss
## [1] 3084119
##
## $betweenss
## [1] 9966055上面你可以看到kmeans函数返回的结果对象的头。下面我将kmeans对象所包含的聚类指数与客户数据框架结合起来,这样我们现在就有3列。这样我们就可以做gg图等。
result_df <- customer_df
result_df$group <- cluster_obj$cluster
head(result_df)## lat long group
## 1 67.260409 47.08063 4
## 2 55.400065 55.46616 4
## 3 -47.152065 -107.63843 1
## 4 -84.266658 -163.62681 1
## 5 -6.012361 103.34046 2
## 6 -10.717590 -59.64681 1我通过在ggplot(使用ggplot2 R包的散点图)中可视化结果来完成这篇文章。对于着色,我使用R中的viridis包。
library(ggplot2)
library(viridis)ggplot(result_df) + geom_point(mapping = aes(x=lat,y=long,color=group)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 
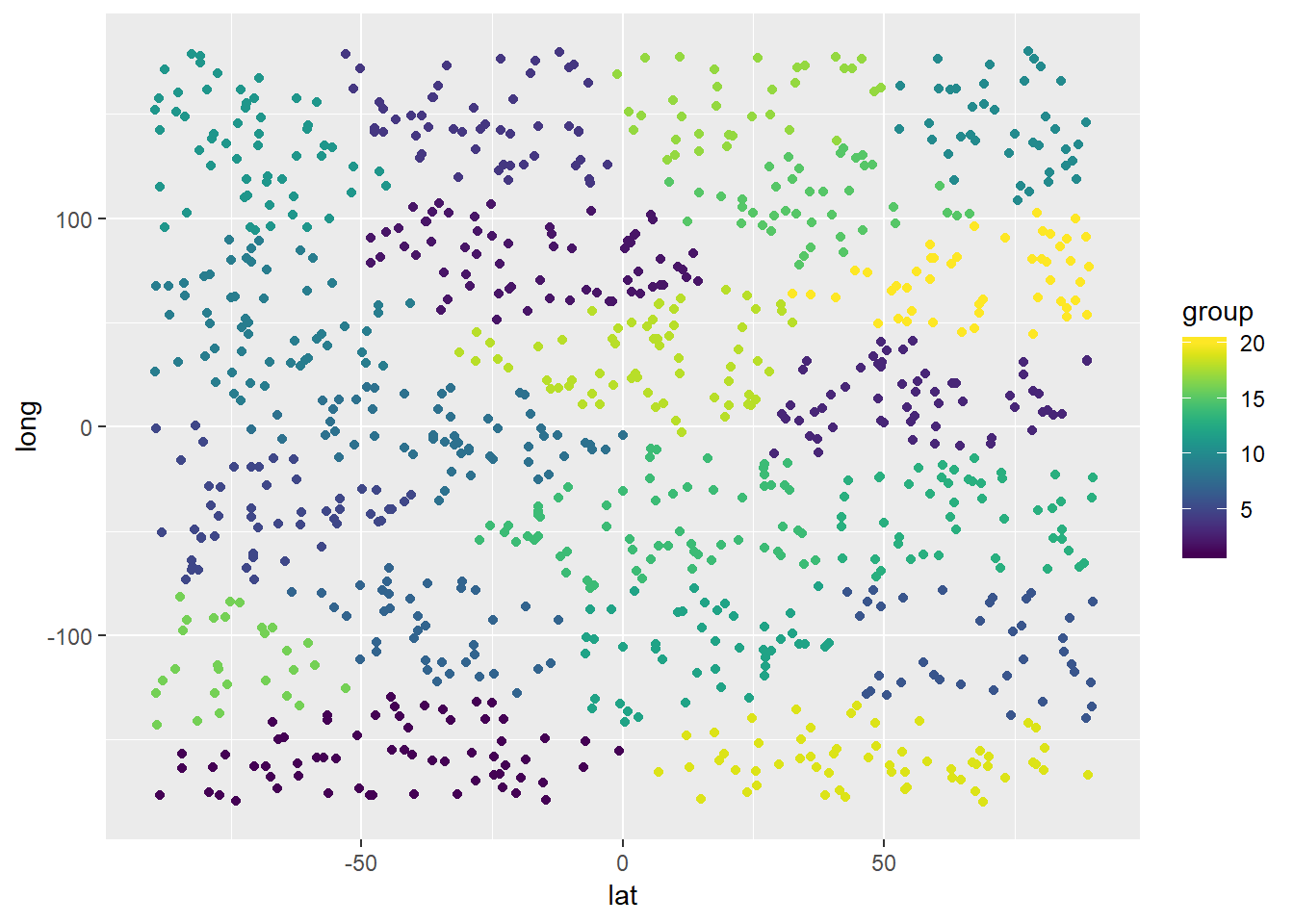
让我们用20个仓库再跑一次测试。
cluster_obj <- kmeans(customer_df,centers=customer_df[initial_centers(customer_df,20),])
result_df$group <- cluster_obj$cluster
ggplot(result_df) + geom_point(mapping = aes(x=lat,y=long,color=group)) +
xlim(-90,90) + ylim(-180,180) + scale_color_viridis(discrete = FALSE, option = "D") + scale_fill_viridis(discrete = FALSE) 
如果有兴趣,可以看看我在R中计算质量中心的帖子,以及如何用R解决仓库位置问题。

专业领域为优化和仿真的工业工程师(R,Python,SQL,VBA)



Leave a Reply