在本文中,我将发布一个脚本,该脚本使用Yahoo Finance的Bayer股票行情自动收录器从Quantmod查询金融股票数据。此外,我使用gtrendsR查询Google搜索强度数据,通过twitteR通过tweet查询,使用GuardianR通过Guardian新闻查询。所有与全球企业拜耳公司有关。我绘制这些数据集之间的关系,应用特征缩放和情感分析进行分析和更好的可视化。
供应链管理人员对本文颇有兴趣,因为在浏览和使用网络时,数字跟踪数据(即作为“跟踪”的“左”数据)与例如供应链风险管理。知道如何查询此类数据有助于建模和防止供应链中断。
首先,我需要在R中加载所需的软件包。
rm(list=ls()) # 清除内存
library(GuardianR) # 将Guardian新闻订阅源流式传输到模型的软件包
library(SentimentAnalysis) # 文本情感分析包vd##
## Attaching package: 'SentimentAnalysis'## The following object is masked from 'package:base':
##
## writelibrary(dplyr) # package for data manipulation ##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionlibrary(ggplot2) # 数据可视化软件包
library(quantmod) # 用于对财务数据进行流传输和建模的软件包 ## Loading required package: xts## Loading required package: zoo##
## Attaching package: 'zoo'## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numeric##
## Attaching package: 'xts'## The following objects are masked from 'package:dplyr':
##
## first, last## Loading required package: TTR## Version 0.4-0 included new data defaults. See ?getSymbols.library(gtrendsR) # 用于流式传输Google趋势数据的程序包
library(twitteR) # 从Twitter查询推文的软件包##
## Attaching package: 'twitteR'## The following objects are masked from 'package:dplyr':
##
## id, location我们将首先查看在《卫报》上发表的与拜耳有关的新闻报道。使用情感分析方法,我评估了这些文章的情感内容,并在很长的时间范围内可视化了分析结果。
为此,我需要设置一个API密钥,在我的脚本中称为“ guardian_key”。v
设置好API密钥后,就可以阅读《卫报》的新闻供稿了。使用GuardianR软件包可以直接在ib R中完成。
news_df <- get_guardian("+Bayer+",from.date="2008-01-01",
to.date ="2019-05-14",
api.key=guardian_key,
section=c("business",
"economy",
"world",
"money"))## [1] "Fetched page #1 of 1"上面的Querry被简化了。对于高性能生产就绪的R脚本,我将应用正则表达式过滤掉包含BAYER术语但与BAYER AG企业无关的文章。
接下来,我们可以计算来自《卫报》的新闻报道的情绪。为此,我在R中应用了SentimentAnalysis程序包。情感分析方法是其自身的科学领域,并且仍在进行大量研究。在R中实现的大多数情感分析方法都使用某种将情感分数与单词匹配的库。另外,一组规则定义了如何对待单词组合。例如。 “不好”具有消极情绪,而“非常好”具有非常积极的情绪。
#使用SentimentAnalysis软件包方法计算情感分数
sentiment_df <- analyzeSentiment(as.character(news_df$body))
#从《卫报》新闻提要中添加日期戳
sentiment_df$date <- as.Date(as.character(news_df$webPublicationDate))《卫报》文章的情感评分取决于准确的情感计算方法。情感计算的差异主要源于以下事实:不同的方法使用不同的基线模型。在基本规则和情感分数到单词的映射中,方法可能有所不同。
下图显示了对于相同的《卫报》新闻提要,各种方法的情感计算之间的差异。此处引用的所有方法均来自SentimentAnalysis软件包。
results_df <- as.data.frame(matrix(nrow=nrow(sentiment_df),ncol=0))
results_df$date <- sentiment_df$date
results_df$GI <- sentiment_df$SentimentGI
results_df$LM <- sentiment_df$SentimentLM
results_df$HE <- sentiment_df$SentimentHE
results_df$QDAP <- sentiment_df$SentimentQDAP
results_df$mean <- (sentiment_df$SentimentGI+sentiment_df$SentimentHE+sentiment_df$SentimentLM+sentiment_df$SentimentQDAP)/4
plotable_df <- as.data.frame(matrix(nrow=nrow(results_df)*5,ncol=0))
plotable_df$date <- c(results_df$date,
results_df$date,
results_df$date,
results_df$date,results_df$date)
plotable_df$score <- c(results_df$GI,
results_df$LM,
results_df$HE,
results_df$QDAP,results_df$mean)
plotable_df$type <- c(rep("GI",times = nrow(results_df)),
rep("LM",times = nrow(results_df)),
rep("HE",times = nrow(results_df)),
rep("QDAP",times = nrow(results_df)),
rep("mean",times = nrow(results_df)))
ggplot(plotable_df) + geom_smooth(mapping=aes(x=date,y=score,color=type)) + ggtitle("Sentiment content of BAYER articles on The Guardian") +
xlab("Time") +
ylab("Sentiment scores")## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
现在,我们继续前进,而不是考虑《卫报》的新闻文章,而是要考虑推文及其情绪。我们只想考虑与拜耳有关的推文,我们首先对拜耳发布的推文进行爬网(即一次可通过REST API获得的推文)。对于此,必须指定一组密钥和令牌。我这样做,然后将值存储到变量“ consumer_key”,“ consumer_secret”,“ access_token”和“ access_secret”。使用这些键,我现在可以访问Bayers tweet时间轴。但是,只有最新的tweet才可以通过R中Twitter的twitteR软件包的开放和免费功能获得。
#通过twitteR软件包查询Twitter。不幸的是,只能使用searchTwitter功能在几天前下载推文
twitter_df <- as.data.frame(matrix(nrow=0,ncol=2))
colnames(twitter_df) <- c("text","created")
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_secret)## [1] "Using direct authentication"timeline_ls <- twitteR::userTimeline("Bayer",n=200000)
twitter_df = rbind(twitter_df,select(twitteR::twListToDF(timeline_ls),text,created))
twitter_df$date <- as.Date(twitter_df$created)
#一些文字清洁
cleaningfunction <- function(x){
return(gsub("[^[:alnum:][:blank:]?&/\\-]", "", x))
}
twitter_df$text <- as.character(lapply(twitter_df$text,cleaningfunction))
#考虑所有四种方法,计算平均情绪得分
twitter_df$sentiment <- (analyzeSentiment(twitter_df$text)$SentimentGI+analyzeSentiment(twitter_df$text)$SentimentHE+analyzeSentiment(twitter_df$text)$SentimentLM+analyzeSentiment(twitter_df$text)$SentimentQDAP)/4
#在时间轴上可视化@Bayer的Twitter情感
ggplot(twitter_df) + geom_smooth(mapping=aes(x=date,y = sentiment)) + ggtitle("Avg. daily sentiment of BAYER tweets") +
xlab("Time") +
ylab("Sentiment score")## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
现在,我搜寻Twitter的搜索功能,以查找提及拜耳的推文-不管推文作者是什么。通过wittR软件包可访问的REST API仅提供最新的tweet。
#通过twitteR软件包查询Twitter。不幸的是,只能使用searchTwitter功能在几天前下载推文
twitter_df <- as.data.frame(matrix(nrow=0,ncol=2))
colnames(twitter_df) <- c("text","created")
search_ls <- twitteR::searchTwitter("@Bayer",n=20000,retryOnRateLimit = 1000000)## [1] "Rate limited .... blocking for a minute and retrying up to 999999 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999998 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999997 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999996 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999995 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999994 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999993 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999992 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999991 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999990 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999989 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999988 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999987 times ..."
## [1] "Rate limited .... blocking for a minute and retrying up to 999986 times ..."twitter_df = rbind(twitter_df,select(twitteR::twListToDF(search_ls),text,created))
twitter_df$date <- as.Date(twitter_df$created)
#一些文字清洁
twitter_df$text <- as.character(lapply(twitter_df$text,cleaningfunction))
#考虑所有四种方法,计算平均情绪得分
twitter_df$sentiment <- (analyzeSentiment(twitter_df$text)$SentimentGI+analyzeSentiment(twitter_df$text)$SentimentHE+analyzeSentiment(twitter_df$text)$SentimentLM+analyzeSentiment(twitter_df$text)$SentimentQDAP)/4
#在时间轴上可视化@Bayer的Twitter情感
twitter_df <- twitter_df %>% group_by(date) %>% summarize(meanSentiment=mean(sentiment))
ggplot(twitter_df) + geom_line(mapping=aes(x=date,y = meanSentiment)) +
ggtitle("Mean sentiment of reply tweets to BAYER") +
xlab("Time") +
ylab("Sentiment score")
我感兴趣的还有另一个数据源。我想看看Google对“ Bayer”一词的搜索强度是如何随着时间变化的。
#查询并使用R包安排Google搜索趋势数据
google_df <- gtrends(keyword = "Bayer AG",time="2010-01-01 2019-05-20")
google_df <- google_df$interest_over_time %>% select(date,hits)
google_df$date <- as.Date(google_df$date)
google_df$hits <- as.numeric(google_df$hits)
#直观地显示“ Bayer AG”在Google搜索中的趋势
ggplot(google_df) + geom_line(mapping=aes(x=date,y=hits)) + ggtitle("Google search intensity index for BAYER") +
xlab("Time") +
ylab("Google trends score (normed, MAX=100)")
Google搜索趋势值是留在Google搜索引擎上的数字迹线的结果。我们可以在例如回归分析
#定义用于功能缩放的函数
feature_scaling <- function(x){
(x-min(x))/(max(x)-min(x))
}
#---设置财务df ---
getSymbols("BAYN.DE",src="yahoo")## 'getSymbols' currently uses auto.assign=TRUE by default, but will
## use auto.assign=FALSE in 0.5-0. You will still be able to use
## 'loadSymbols' to automatically load data. getOption("getSymbols.env")
## and getOption("getSymbols.auto.assign") will still be checked for
## alternate defaults.
##
## This message is shown once per session and may be disabled by setting
## options("getSymbols.warning4.0"=FALSE). See ?getSymbols for details.##
## WARNING: There have been significant changes to Yahoo Finance data.
## Please see the Warning section of '?getSymbols.yahoo' for details.
##
## This message is shown once per session and may be disabled by setting
## options("getSymbols.yahoo.warning"=FALSE).## [1] "BAYN.DE"finance_df <- as.data.frame(BAYN.DE)
finance_df$source = rep("quantmod",nrow(finance_df))
finance_df$date <- as.Date(rownames(finance_df))
#功能缩放
finance_df <- finance_df %>% select(date,BAYN.DE.Adjusted,source)
colnames(finance_df) <- c("date","value","source")
finance_df$value <- feature_scaling(finance_df$value)
#---建立监护人情绪df ---
guardianSenti_df <- dplyr::filter(plotable_df,type=="mean")
guardianSenti_df$source <- rep("guardian",nrow(guardianSenti_df))
guardianSenti_df$date <- as.Date(guardianSenti_df$date)
#功能缩放
guardianSenti_df <- guardianSenti_df %>% select(date,score,source)
colnames(guardianSenti_df) <- c("date","value","source")
guardianSenti_df$value <- feature_scaling(guardianSenti_df$value)
#-设置Google Trends df-
gtrends_df <- google_df %>% select(date,hits)
colnames(gtrends_df) <- c("date","value")
gtrends_df$date <- as.Date(gtrends_df$date)
gtrends_df$source <- rep("google",nrow(gtrends_df))
#功能缩放
gtrends_df$value <- feature_scaling(gtrends_df$value)
#---设置Twitter情感df-
twitterSenti_df <- twitter_df %>% select(date,meanSentiment)
colnames(twitterSenti_df) <- c("date","value")
twitterSenti_df$source <- rep("twitter",nrow(twitterSenti_df))
twitterSenti_df$date <- as.Date(twitterSenti_df$date)
# feature scaling
twitterSenti_df$value <- feature_scaling(twitterSenti_df$value)
#合并框架
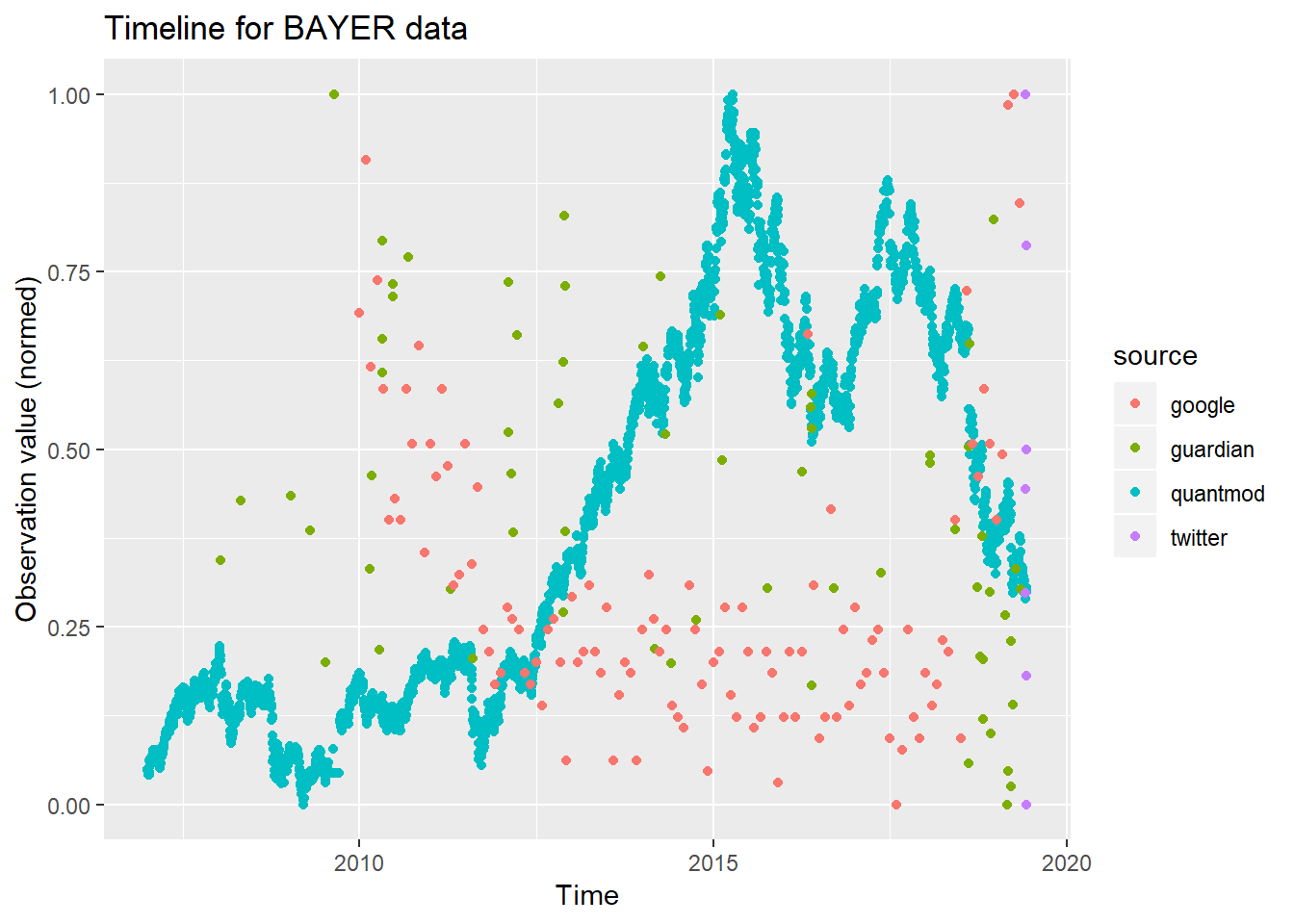
combined_df <- rbind(finance_df,
guardianSenti_df,
gtrends_df,
twitterSenti_df)
#可视化-有相关性吗?
ggplot(combined_df) + geom_point(mapping=aes(x=date,y=value,color=source)) + ggtitle("Timeline for BAYER data") +
xlab("Time") +
ylab("Observation value (normed)")
在接下来的步骤中,可以使用回归分析(包括来自时间序列分析的回归模型)继续进行分析。在我的博客上,您也可以找到有关R中回归分析的文章。

专业领域为优化和仿真的工业工程师(R,Python,SQL,VBA)
Leave a Reply