“OECD”是 R 中的一个包,提供了一个直接从 R 代码执行查询的接口。在这篇文章中,我使用“OECD”包来分析欧洲运输数据。
我首先阅读 R 中的 OECD 包。它包含一个函数“search_dataset”,我想了解它可以做什么:
library(OECD)
?search_dataset“search_dataset”允许我们根据作为第一个参数提供给函数的搜索字符串来搜索数据集。“search_dataset”将返回一个数据框作为返回输出。让我们使用该函数来查找包含有趣的传输数据的数据集。
head(search_dataset("transport"))## id
## 80 AIRTRANS_CO2
## 385 ETCR
## 452 MTC
## 482 CIF_FOB_ITIC
## 900 ITF_PASSENGER_TRANSPORT
## 934 ITF_GOODS_TRANSPORT
## title
## 80 Air Transport CO2 Emissions
## 385 Regulation in energy, transport and communications 2013
## 452 Maritime Transport Costs
## 482 International Transport and Insurance Costs of Merchandise Trade (ITIC)
## 900 Passenger transport
## 934 Freight transport对于手头帖子中的文章,我想使用“ITF_GOODS_TRANSPORT”数据集(货运)。我使用“get_data_structure”函数查询它:
data_struct <- get_data_structure("ITF_GOODS_TRANSPORT")
typeof(data_struct)## [1] "list"让我们看看列表的内容:
str(data_struct)## List of 9
## $ VAR_DESC :'data.frame': 9 obs. of 2 variables:
## ..$ id : chr [1:9] "COUNTRY" "VARIABLE" "YEAR" "OBS_VALUE" ...
## ..$ description: chr [1:9] "Country" "Variable" "Year" "Observation Value" ...
## $ COUNTRY :'data.frame': 58 obs. of 2 variables:
## ..$ id : chr [1:58] "ALB" "ARG" "ARM" "AUS" ...
## ..$ label: chr [1:58] "Albania" "Argentina" "Armenia" "Australia" ...
## $ VARIABLE :'data.frame': 14 obs. of 2 variables:
## ..$ id : chr [1:14] "T-GOODS-TOT-INLD" "T-GOODS-RL-TOT" "T-GOODS-RD-TOT" "T-GOODS-RD-REW" ...
## ..$ label: chr [1:14] "Total inland freight transport" "Rail freight transport" "Road freight transport" "Road freight transport for hire and reward" ...
## $ YEAR :'data.frame': 49 obs. of 2 variables:
## ..$ id : chr [1:49] "1970" "1971" "1972" "1973" ...
## ..$ label: chr [1:49] "1970" "1971" "1972" "1973" ...
## $ OBS_STATUS :'data.frame': 16 obs. of 2 variables:
## ..$ id : chr [1:16] "c" "B" "C" "D" ...
## ..$ label: chr [1:16] "Internal estimate" "Break" "Non-publishable and confidential value" "Difference in methodology" ...
## $ UNIT :'data.frame': 316 obs. of 2 variables:
## ..$ id : chr [1:316] "1" "GRWH" "AVGRW" "IDX" ...
## ..$ label: chr [1:316] "RATIOS" "Growth rate" "Average growth rate" "Index" ...
## $ POWERCODE :'data.frame': 32 obs. of 2 variables:
## ..$ id : chr [1:32] "0" "1" "2" "3" ...
## ..$ label: chr [1:32] "Units" "Tens" "Hundreds" "Thousands" ...
## $ REFERENCEPERIOD:'data.frame': 92 obs. of 2 variables:
## ..$ id : chr [1:92] "2013_100" "2012_100" "2011_100" "2010_100" ...
## ..$ label: chr [1:92] "2013=100" "2012=100" "2011=100" "2010=100" ...
## $ TIME_FORMAT :'data.frame': 5 obs. of 2 variables:
## ..$ id : chr [1:5] "P1Y" "P1M" "P3M" "P6M" ...
## ..$ label: chr [1:5] "Annual" "Monthly" "Quarterly" "Half-yearly" ...OECD 提供的数据有很多方面。这就是我使用 get_data_structure 的原因——了解“ITS_GOODS_TRANSPORT”数据集中提供的数据的维度和结构。
让我们继续查询实际数据集,应用相关过滤器。为此,我使用“OECD”R 包提供的“get_dataset”函数:
data_df <- as.data.frame(get_dataset(dataset = "ITF_GOODS_TRANSPORT"))
head(data_df)## COUNTRY VARIABLE TIME_FORMAT UNIT POWERCODE obsTime obsValue
## 1 MKD T-CONT-SEA-TON P1Y TONNE 3 1970 NA
## 2 MKD T-CONT-SEA-TON P1Y TONNE 3 1971 NA
## 3 MKD T-CONT-SEA-TON P1Y TONNE 3 1972 NA
## 4 MKD T-CONT-SEA-TON P1Y TONNE 3 1973 NA
## 5 MKD T-CONT-SEA-TON P1Y TONNE 3 1974 NA
## 6 MKD T-CONT-SEA-TON P1Y TONNE 3 1975 NA
## OBS_STATUS
## 1 M
## 2 M
## 3 M
## 4 M
## 5 M
## 6 M让我们过滤掉一些相关的数据子集:
backup_df <- data_df
library(dplyr)
colnames(data_df) <- c("country","variable","timeformat","unit","powercode","obsTime","obsValue","obsStatus")
data_df <- dplyr::filter(data_df,country=="DEU")
data_df <- dplyr::filter(data_df,timeformat=="P1Y")
data_df <- dplyr::filter(data_df,unit=="TONNEKM")
data_df <- data_df[is.na(data_df$obsStatus),]
unique(data_df$variable)## [1] "T-GOODS-RL-TOT" "T-GOODS-RD-REW" "T-GOODS-TOT-INLD" "T-GOODS-PP-TOT"
## [5] "T-GOODS-IW-TOT" "T-GOODS-RD-TOT" "T-SEA-CAB" "T-GOODS-RD-OWN"我们进行了大量子集化,但剩余的数据框仍然包含不同的变量。如果我们想详细了解这些,我们必须回到结构对象,即“data_struct”对象:
data_struct$VARIABLE## id label
## 1 T-GOODS-TOT-INLD Total inland freight transport
## 2 T-GOODS-RL-TOT Rail freight transport
## 3 T-GOODS-RD-TOT Road freight transport
## 4 T-GOODS-RD-REW Road freight transport for hire and reward
## 5 T-GOODS-RD-OWN Road freight transport on own account
## 6 T-GOODS-IW-TOT Inland waterways freight transport
## 7 T-GOODS-PP-TOT Pipelines transport
## 8 T-SEA-CAB Coastal shipping (national transport)
## 9 T-SEA Maritime transport
## 10 T-CONT-RL-TEU Rail containers transport (TEU)
## 11 T-CONT Containers transport
## 12 T-CONT-RL-TON Rail containers transport (weight)
## 13 T-CONT-SEA-TEU Maritime containers transport (TEU)
## 14 T-CONT-SEA-TON Maritime containers transport (weight)这意味着我们不仅有货运总和的数据,还有相关子类别的数据。我们将使用它在其他帖子中进行进一步分析。在这篇文章中,我们想继续分析内陆货运总量。
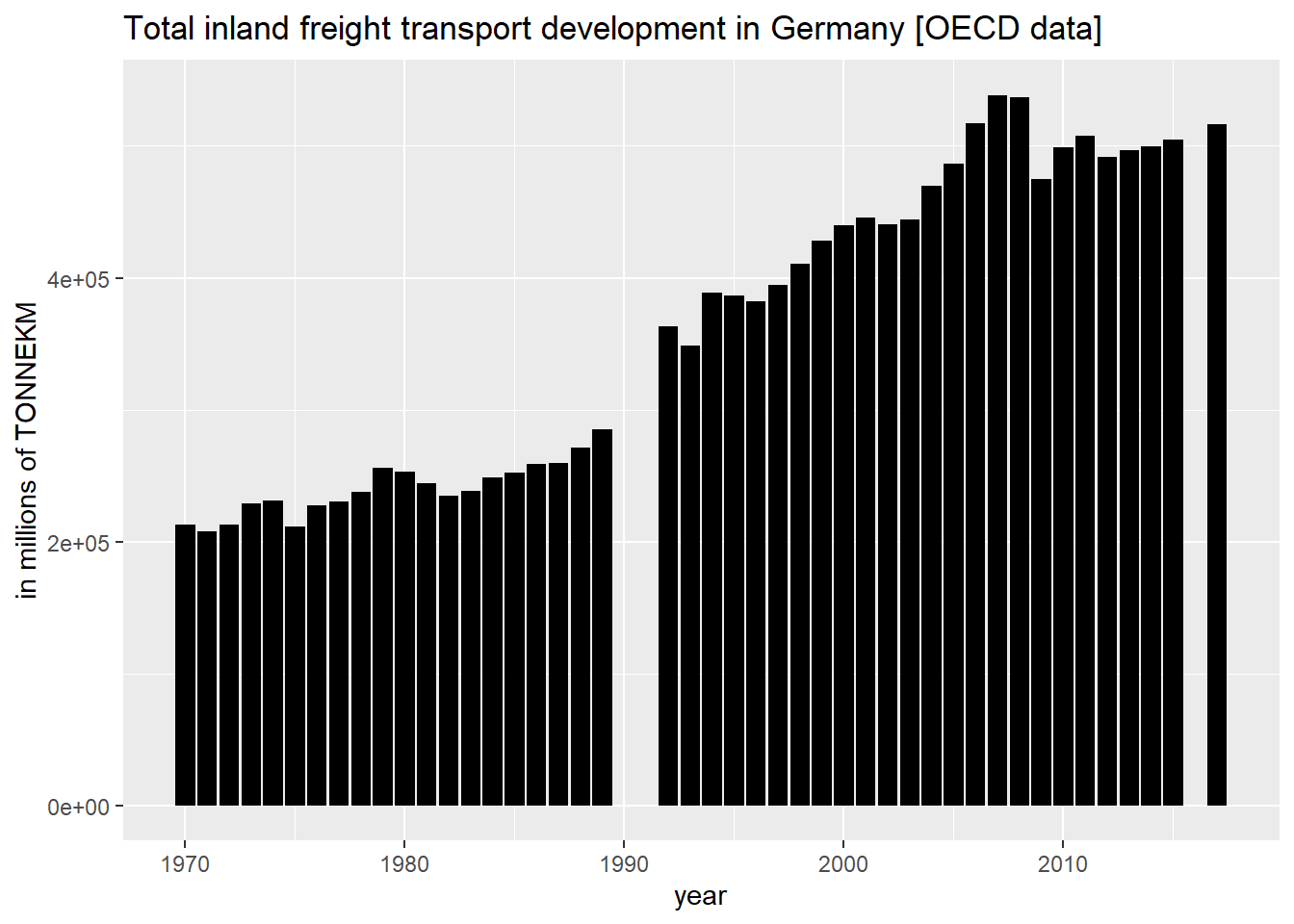
下图显示了德国内陆货运总吨公里 [TONNEKM] 的时间序列,单位为百万(powercode 6):
library(ggplot2)
ggplot(filter(data_df,variable=="T-GOODS-TOT-INLD")) +
geom_col(mapping = aes(x=as.numeric(obsTime),y=obsValue),fill="black") +
ggtitle("Total inland freight transport development in Germany [OECD data]") +
xlab("year") +
ylab("in millions of TONNEKM")
除了 OECD R 包之外,您可能还想检查 R 中的fredr包。Fredr是另一个用于访问公共经济数据的 R 包,提供对 FRED 数据库的访问。

专业领域为优化和仿真的工业工程师(R,Python,SQL,VBA)



Leave a Reply